索引作用
提供了类似于书中目录的作用,目的是为了优化查询
索引的种类(算法)
B数索引
Hash索引
R树
Full text
GIS
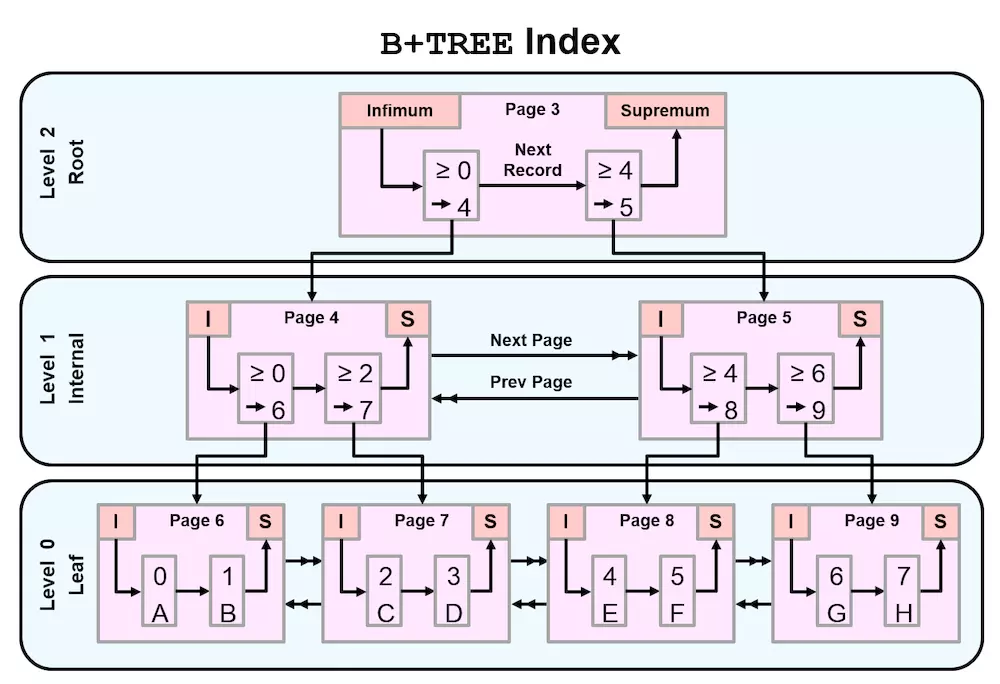
B-Tree
B+Tree 在范围查询方面提供了更好的性能(> < >= <= like)
B*Tree
在功能上的分类
B树就像是倒过来的树一样,上层是根节点,中层是枝节点,底层是叶子节点
辅助索引(s)怎么构建B树结构的?
1.索引是基于表中,列的值生成的B树结构
2.首先提取此列所有的值,进行自动排序
3.将排好序的值,均匀分布到索引树的叶子节点中(16k)
4.然后生成此索引键值所对应后端数据页的指针
5.生成枝节点和根节点,根据数据量级和索引键长度,生成合适的索引树高度
聚集索引(c)怎么构建B树结构的?
前提:
1.表中设置了主键,主键列就会自动被作为聚集索引
2.如果没有主键,会选择唯一键作为聚集索引
3.聚集索引必须在建表时才有意义,一般是表的无关列(ID)
构建:
1.在建表时,设置了主键列
2.在将来录入数据时,就会按照ID列的顺序存储到磁盘上(又称为聚集索引组织表)
3.将排好序的整行数据,生成叶子节点,可以理解为,磁盘的数据页就是叶子节点
聚集索引和辅助索引构成区别:
1.聚集索引只能有一个,非空唯一,一般是主键
2.辅助索引,可以有多个,是配合聚集索引使用的
3.聚集索引的叶子节点,就是真正的磁盘数据行存储的数据页
4.mysql是根据聚集索引,组织存储数据,数据存储时就是按照聚集索引的顺序进行存储数据
5.辅助索引,只会提取索引键值,进行自动排序生成B树结构
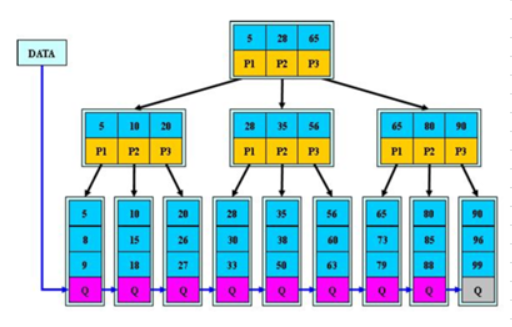
辅助索引细分:
1.普遍的单列辅助索引
2.联合索引:多个列作为索引条件,生成索引树,理论上设计的好的,可以减少大量的回表查询
3.唯一索引:索引列的值就是唯一的
关于索引树的高度受什么影响:
1.数据量级过大,可以分表,分库,分布式
2.索引列值过长,可以使用前缀索引
3.数据类型
索引的管理
查看索引 db01 [world]>desc city; +-------------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------------+----------+------+-----+---------+----------------+ | ID | int(11) | NO | PRI | NULL | auto_increment | | Name | char(35) | NO | | | | | CountryCode | char(3) | NO | MUL | | | | District | char(20) | NO | | | | | Population | int(11) | NO | | 0 | | +-------------+----------+------+-----+---------+----------------+ 5 rows in set (0.00 sec) Field:列名字 Key:有没有索引,索引类型 PRI:主键索引 UNI:唯一索引 MUL:辅助索引(单列,联合,前缀)
创建索引: ind_name(name); 前面是索引的名字,括号中是要建立索引的列名 3306 [world]>alter table city add index ind_name(name); Query OK, 0 rows affected (0.38 sec) Records: 0 Duplicates: 0 Warnings: 0 3306 [world]>show index from city; +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | city | 0 | PRIMARY | 1 | ID | A | 4188 | NULL | NULL | | BTREE | | | | city | 1 | CountryCode | 1 | CountryCode | A | 232 | NULL | NULL | | BTREE | | | | city | 1 | ind_name | 1 | Name | A | 3998 | NULL | NULL | | BTREE | | | +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 不建议在一个列上建立多个索引 同一个表中,索引名字不能相同
删除索引: 3306 [world]>alter table city drop index ind_name; Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0
覆盖索引(联合索引) 3306 [world]>alter table city add index idx_co_po(countrycode,population); 3306 [world]>3306 [world]>show index from city; +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | city | 0 | PRIMARY | 1 | ID | A | 4188 | NULL | NULL | | BTREE | | | | city | 1 | CountryCode | 1 | CountryCode | A | 232 | NULL | NULL | | BTREE | | | | city | 1 | idx_co_po | 1 | CountryCode | A | 232 | NULL | NULL | | BTREE | | | | city | 1 | idx_co_po | 2 | Population | A | 4052 | NULL | NULL | | BTREE | | | +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 4 rows in set (0.00 sec)
前缀索引: 3306 [world]>alter table city add index idx_di(district(5)); Query OK, 0 rows affected (0.25 sec) Records: 0 Duplicates: 0 Warnings: 0 3306 [world]>3306 [world]>show index from city; +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | city | 0 | PRIMARY | 1 | ID | A | 4188 | NULL | NULL | | BTREE | | | | city | 1 | CountryCode | 1 | CountryCode | A | 232 | NULL | NULL | | BTREE | | | | city | 1 | idx_di | 1 | District | A | 1225 | 5 | NULL | | BTREE | | | +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
唯一索引: 3306 [world]>alter table city add unique index idx_unil(name); ERROR 1062 (23000): Duplicate entry 'San Jose' for key 'idx_unil' 出现报错,因为有重复行,所以建不了唯一索引,需要删除重复行,在进行创建
执行计划
介绍
获取到的是优化器选择完成的,认为代价最小的执行计划
作用
语句执行前,先看执行计划信息,可以有效的防止性能较差的语句带来的性能问题
如果业务中出现了慢语句,我们也需要借助此命令进行语句的评估,分析优化方案
显示计划
explain +查询命令
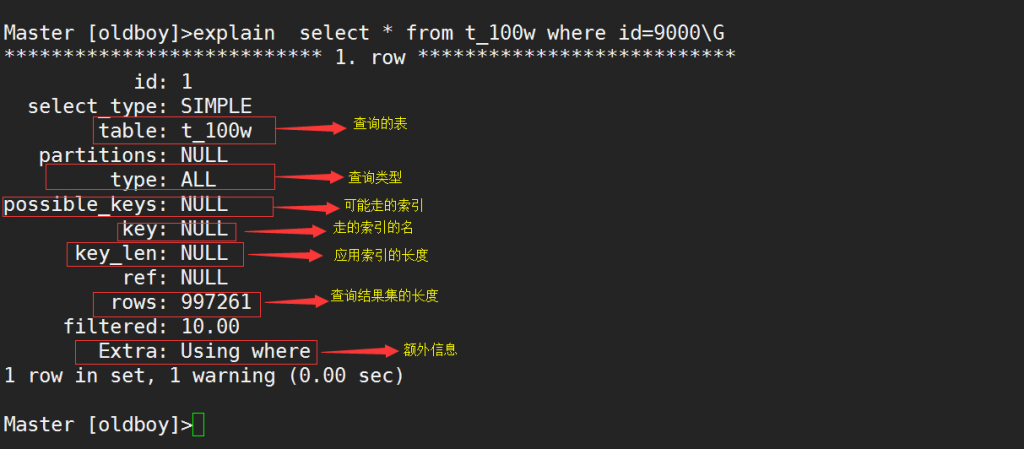
TYPE类型
ALL: 全表扫描,不走索引
例子:
1. 查询条件列,没有索引 SELECT * FROM t_100w WHERE k2='780P';
2. 查询条件出现以下语句(辅助索引列)
USE world
DESC city; DESC SELECT * FROM city WHERE countrycode <> 'CHN';
DESC SELECT * FROM city WHERE countrycode NOT IN ('CHN','USA');
DESC SELECT * FROM city WHERE countrycode LIKE '%CH%';
注意:对于聚集索引列,使用以上语句,依然会走索引
DESC SELECT * FROM city WHERE id <> 10;
INDEX : 全索引扫描
1. 查询需要获取整个索引树种的值时:
DESC SELECT countrycode FROM city;
2. 联合索引中,任何一个非最左列作为查询条件时:
idx_a_b_c(a,b,c) ---> a ab abc
SELECT * FROM t1 WHERE b
SELECT * FROM t1 WHERE c
RANGE : 索引范围扫描
辅助索引> < >= <= LIKE IN OR
主键 <> NOT IN
例子:
1. DESC SELECT * FROM city WHERE id<5;
2. DESC SELECT * FROM city WHERE countrycode LIKE 'CH%';
3. DESC SELECT * FROM city WHERE countrycode IN ('CHN','USA');
注意: 1和2例子中,可以享受到B+树的优势,但是3例子中是不能享受的.
所以,我们可以将3号列子改写:
DESC SELECT * FROM city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM city WHERE countrycode='USA'; ref:
非唯一性索引,等值查询
DESC SELECT * FROM city WHERE countrycode='CHN'; eq_ref:
在多表连接时,连接条件使用了唯一索引(uk pK)
DESC SELECT b.name,a.name FROM city AS a JOIN country AS b
ON a.countrycode=b.code
WHERE a.population <100;
DESC country
system,const :
唯一索引的等值查询 DESC SELECT * FROM city WHERE id=10;
explain(desc)使用场景
mysql出现性能问题
应急性的慢,hang住了
一段时间慢,持续性的
show processlist获取到导致数据库hang的语句
explain分析SQL的执行计划,有没有走索引,索引的类型情况
建立索引的原则
建表时一定要有主键,一般是无关列 *****
选择唯一性索引 ***** 唯一性索引的值是唯一的,可以更快速的通过索引来确定某条记录 例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。 如果使用姓名的话,可能存在同名现象,从而降低查询速度。
优化方案:
(1) 如果非得使用重复值较多的列作为查询条件(例如:男女),可以将表逻辑拆分
(2) 可以将此列和其他的查询类,做联和索引
为经常需要where 、ORDER BY、GROUP BY,join on等操作的字段 排序操作会浪费很多时间。 where A B C ---> A B C in where A group by B order by C A,B,C 如果为其建立索引,优化查询
注:如果经常作为条件的列,重复值特别多,可以建立联合索引。
尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。
限制索引的数目
索引的数目不是越多越好。
可能会产生的问题:
(1) 每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。
(2) 修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
(3) 优化器的负担会很重,有可能会影响到优化器的选择.
percona-toolkit中有个工具,专门分析索引是否有用
删除不在使用或很少使用的索引
pt-duplicate-key-checker
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理 员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
大表加索引,要在不繁忙期间操作
尽量少在经常更新值的列上建索引
不走索引的情况
没有查询条件,或者查询条件列没有建立索引
select * from tab; 全表扫描。
select * from tab where 1=1;
在业务数据库中,特别是数据量比较大的表。 是没有全表扫描这种需求。
1、对用户查看是非常痛苦的。
2、对服务器来讲毁灭性的。
(1) select * from tab;
SQL改写成以下语句:
select * from tab order by price limit 10 ; 需要在price列上建立索引
(2) select * from tab where name='zhangsan' name列没有索引
改:
1、换成有索引的列作为查询条件
2、将name列建立索引
查询结果集是原表中的大部分数据,应该是25%以上 查询的结果集,超过了总数行数25%,优化器觉得就没有必要走索引了。
假如:tab表 id,name id:1-100w ,id列有(辅助)索引
select * from tab where id>500000;
如果业务允许,可以使用limit控制。
怎么改写 ?
结合业务判断,有没有更好的方式。如果没有更好的改写方案 尽量不要在mysql存放这个数据了。放到redis里面。
索引本身失效,统计数据不真实 索引有自我维护的能力。
对于表内容变化比较频繁的情况下,有可能会出现索引失效。
一般是删除重建
现象:
有一条select语句平常查询时很快,突然有一天很慢,会是什么原因
select? --->索引失效,,统计数据不真实
DML ? --->锁冲突
查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等) 例子: 错误的例子:select * from test where id-1=9; 正确的例子:select * from test where id=10; 算术运算 函数运算 子查询
<> ,not in 不走索引(辅助索引) EXPLAIN SELECT * FROM teltab WHERE telnum <> '110';
EXPLAIN SELECT * FROM teltab WHERE telnum NOT IN ('110','119');
mysql> select * from tab where telnum <> '1555555';
+------+------+---------+
| id | name | telnum |
+------+------+---------+
| 1 | a |1333333 |
+------+------+---------+
1 row in set (0.00 sec)
mysql> explain select * from tab where telnum <> '1555555';
单独的>,<,in 有可能走,也有可能不走,和结果集有关,尽量结合业务添加limit or或in 尽量改成union
EXPLAIN SELECT * FROM teltab WHERE telnum IN ('110','119');
改写成:
EXPLAIN SELECT * FROM teltab WHERE telnum='110'
UNION ALL
SELECT * FROM teltab WHERE telnum='119'
like "%_" 百分号在最前面不走
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '31%'
走range索引扫描
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '%110'
不走索引
%linux%类的搜索需求,可以使用elasticsearch+mongodb 专门做搜索服务的数据库产品