什么是执行计划?
select * from t1 where name=''zs; 分析的是优化器按照内置的cost代价计算算法,最终选择后的认为代价最小最优的执行计划。是辅助优化手段 cost就是代价成本的意思,对于计算机来说,代价是IO,CPU,内存。 作用: 语句执行前,先看执行计划信息,可以有效的防止性能较差的语句带来的性能问题。 如果业务中出现了慢语句,我们也需要借助此命令进行语句的评估,分析优化方案。 语句运行好坏和执行计划密切相关,执行计划分析完再让其运行,获取执行计划就是语句在执行过程中的优化器位置获取。
查看执行计划
desc select * from t_100w world.city; explain select * from t_100w world.city;
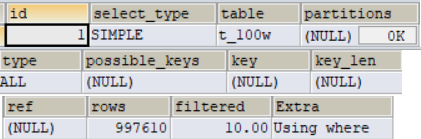
执行计划显示结果的认识
table 此次查询涉及的表
type 查询的类型,全表扫描或者索引扫描
possiable_keys 可能会用到的索引:判断走没走索引,没用到索引的可以清除
key 之后选择使用的索引:判断走的索引是否合理
key_len 索引覆盖的长度 --判断联合索引是否合理
rows 此次查询需要扫描的行数
extra 额外的信息
详解table
此次查询涉及到的表,针对一个查询中多个表时,精确找到问题表 desc select country.name,city.name from city join country on city.countrycode=country.code where city.population='CHN';
详解type 查询类型
全表扫描:不用任何的索引ALL 索引扫描:index<range<ref<eq_ref<const(system) 至少保证range及以上索引级别
ALL
全表扫描,不走索引,需要处理
1. 查询条件列,没有索引
desc select * from t_100w where k2='34ab';
2. 查询条件出现以下语句(辅助索引列)
use world;
desc city;
desc select * from city where countrycode <> 'CHN';
desc select * from city where countrycode not in ('CHN','USA');
desc select * from city where countrycode like '%CH%';
注意:对于聚集索引列,使用这种语句,依然会走索引,早期版本也不走,新版本都走索引
desc select * from city where id <>10;
INDEX
全索引扫描,就像所有的书目录先全部看一遍 查询需要获取整个索引树中的值时: DESC SELECT countrycode FROM city; 联合索引中,任何一个非最左列作为查询条件时: idx_a_b_c(a,b,c) ---> a ab abc SELECT * FROM t1 WHERE b SELECT * FROM t1 WHERE c
RANGE
索引范围扫描
辅助配合索引>=,<=,like,in,or
1.desc SELECT * FROM city WHERE id<5;
2.desc SELECT * FROM city WHERE countrycode LIKE 'CH%';
3.desc SELECT * FROM city WHERE countrycode IN('CHN','USA');
注意:
1和2例子中,可以享受到B+树叶子节点双向指针的优势,但是3例子中是不能享受的,因为查找条件是不连续的。
所以,我们可以将3号列子改写:
DESC SELECT * FROM city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM city WHERE countrycode='USA';
主键配合>,<,<>,not in
ref
非唯一性普通 辅助索引配合等值查询 DESC SELECT * FROM city WHERE countrycode='CHN'
eq_ref
在多表连接时,非驱动表链接条件是主键或者唯一键,join连接条件使用了唯一索引(uk pK) DESC SELECT country.name,city.name FROM city JOIN country ON city.countrycode=country.code WHERE city.population <100; 因为city表的countrycode列为country表中的主键,但是city表索引类型依然是ALL
const(system)
system和const为一样的级别,是唯一索引的等值查询,聚簇索引等值查询 DESC SELECT * FROM city WHERE id=10;
NULL
不返回数据的时候性能最好 DESC SELECT * FROM city WHERE id=-10;
详解possiable_keys,key
possible_keys:可能会走的索引,所有 和此次查询有关的索引 key:此次查询选择的索引。
详解key_len
联合索引覆盖长度
对于联合索引index(a,b,c),希望将来的查询语句,对于联合索引应用的越充分越好。
key_len 可以帮助我们判断,此次查询,走了联合索引的几部分。
key_len的计算:idx(a,b,c)
select * from t1 where a= and b= and c=
key_len=a长度+b长度+c长度
长度指的是什么?
长度受到数据类型,字符集影响,指的是列的最大字节储值长度,not null为预留一个字节存字符长度
数字:tinyint存1个字节,int存4个字节,bigint存8字节
字符:utf8(utf8mb4)-->一个字符最大占3(4)个字节
not null 没有notnull
char(10) 3*10 3*10+1
varchar(10) 3*10+2 3*10+2+1
b char(10) not null 30
b char(10) 31
c varchar(10) not null 32
c varchar(10) 33

extra 额外的信息-filesort 文件排序
using filesort:表示此次查询使用到了文件排序,说明在查询中的排序操作:order by group by distinct... DESC SELECT * FROM city WHERE countrycode='CHN' ORDER BY population; 索引生成B树结构时,需要对整个列值进行排序,排序完落到叶子节点均匀存储show index from city; alter table city drop index CountryCode; alter table city add index idx_c_p(countrycode,population); DESC SELECT * FROM city WHERE countrycode='CHN' ORDER BY population;
结论 1.当我们看到执行计划extra位置出现filesort,说明由文件排序出现,是没有走索引的 2.观察需要排序(ORDER BY,GROUP BY ,DISTINCT )的条件,有没有索引 3. 根据子句的执行顺序,去创建联合索引,删除原来的单列索引 4.如果查询语句中包含having,则只需要给having前的条件添加联合索引,后面的order by即使添加也不走索引 解决办法:把having前面查询的值构建一个临时表(create temporary table xxxx as 分割出来的having前的语句), having表改为where语句,然后把临时表与where后面的order by构建一个联合索引
根据业务分析哪个表和列建立什么样的索引,业务主要包括产品的功能和用户的行为,找到"热"查询语句中较慢的语句,可以通过slowlog日志工具查看。"热"数据主要看架构分布式怎么设计
开发规范:注意哪些sql语句不会走索引即使有索引也不走
explain(desc)使用场景(面试题)
题目意思: 我们公司业务慢,请你从数据库的角度分析原因
第一种情况:应急性的慢:突然夯住
应急情况:数据库夯住(卡了,资源耗尽),观察CPU,内存可以看出 处理过程: 1.show processlist; 获取到导致数据库hang的语句 主要看command列的query行,time列的运行时间长短,info列为导致数据库夯住的语句 可以用show full processlist;显示info列为导致数据库夯住的完整语句 临时解决:kill id号; 2. 根本解决问题,explain 分析SQL的执行计划,有没有走索引,索引的类型情况 3. 建索引,改语句
第二种情况:一段时间慢(持续性的):
(1)记录慢日志slowlog,分析slowlog观察时间段, (2)explain 分析SQL的执行计划,有没有走索引,索引的类型情况 (3)建索引,改语句