1 课程目标
• 了解 GBase 8c 数据库 Plan Hint 功能
• Plan Hint 的介绍
• Plan Hint 的使用
• 备注:课程功能分布式和单机都适用
2 Plan Hint介绍
• Plan Hint 为用户提供了直接影响执行计划的手段,用户可以通过指定 join 顺序,join、scan 方法,指定行数等手段来进行执行计划调优,以提升查询性能;
• 指定形式:/*+ <plan hint>*/
• 支持范围:
‒ 指定 join 方式;
‒ 指定 join 顺序;
‒ 指定行数;
‒ 指定 scan 方式;
‒ 指定链接块名;
‒ custom plan 和 generic plan 选择的 hint;
‒ 指定子查询不扩展;
3 使用Plan Hint
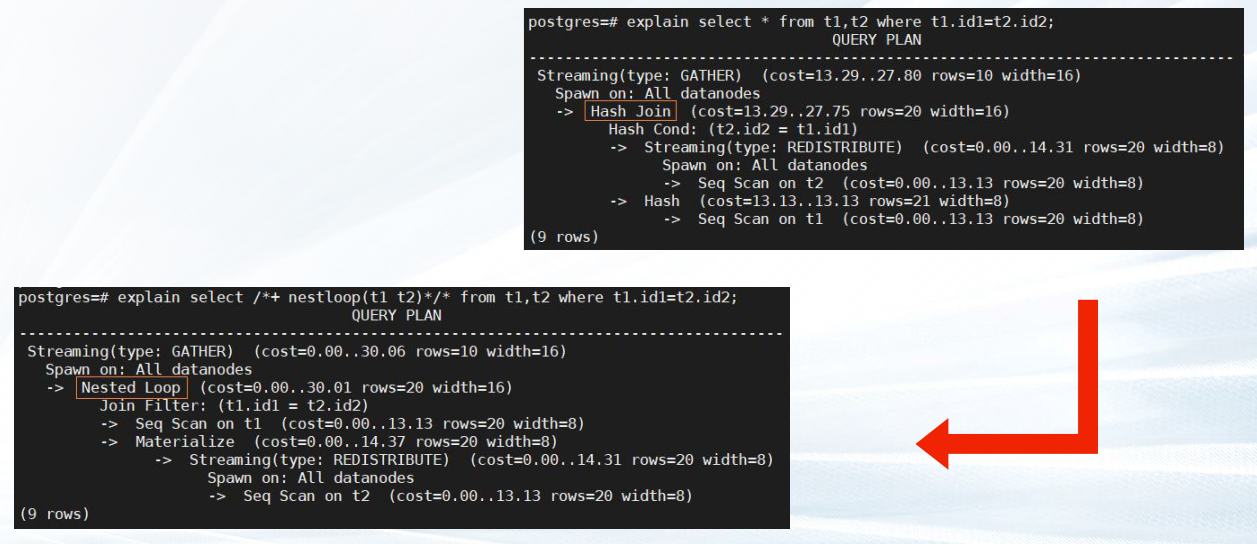
—3.1 指定join方式
语法
[no] nestloop | hashjoin | mergejoin (table_list)
✔no 表示不使用hint的join方式。
✔ 支持常用的join,包括Hash Join、Nested Join 、Merge Join。
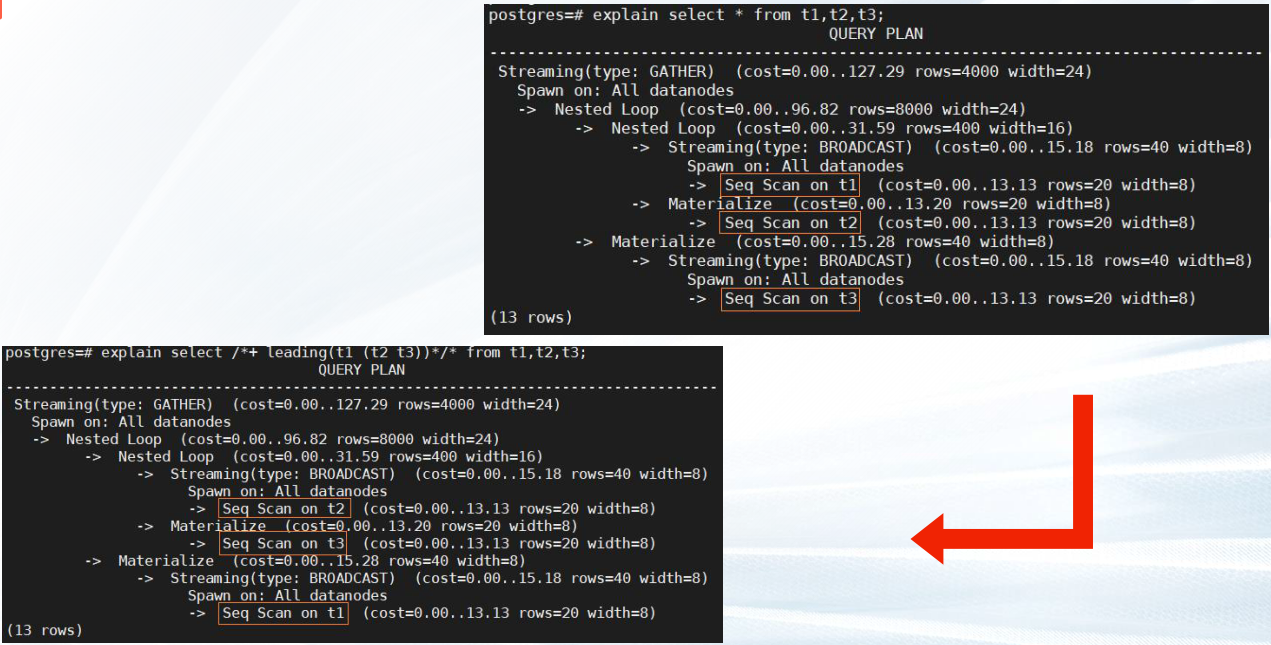
—3.2 指定join顺序
语法
✔不指定内外表顺序
leading(join_table_list)
✔ 同时指定join顺序和内外表顺序
leading((join_table_list))
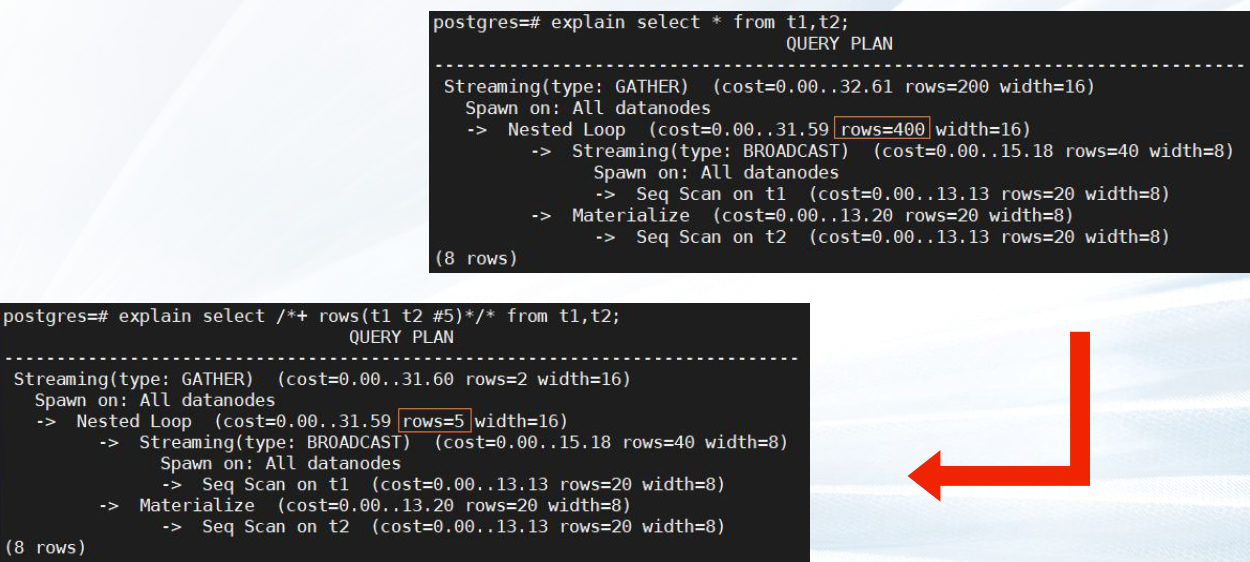
—3.3 指定行数
语法
rows(table_list #|+|-|* const)
✔# 表示直接使用后面的行数进行hint。
✔+,-,* 表示对原来估算的行数进行加、减、乘操作
✔const常量可以是任意非负数,支持科学计数法。
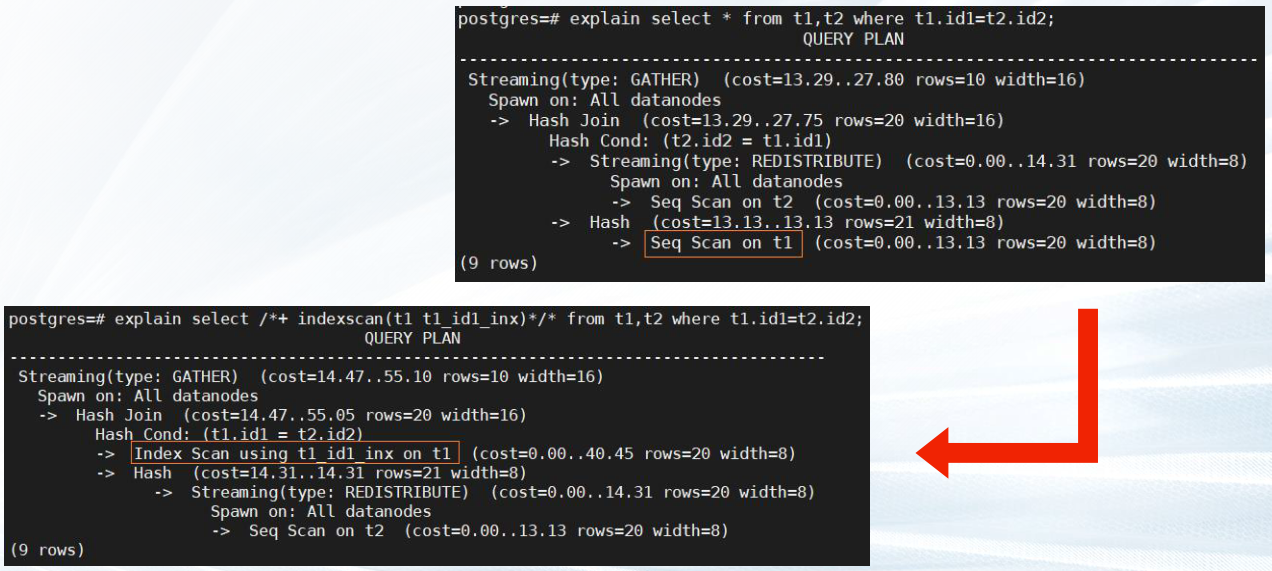
—3.4 指定扫描方式
语法
[no] <scan_type> (table [index])
✔ no表示不使用hint的scan方式。
✔ <scan_type> 支持常用的 tablescan、indexscan、indexonlyscan。
✔ table表示hint指定的表,只能指定一个表,如果表存在别名应优先使用别名进行 hint。
—3.5 指定链接块名
语法
blockname (table)
✔table表示为该子链接块hint的别名的名称。
—3.6 custom plan与generic plan
• 如果同样的一条 SQL,可能只是查询条件入参不同,要执行很多遍,每次都是同样的执行计划、每次都发生硬解析,则会消耗大量时间。
针对这种查询,可以使用 PBE 的方式执行,来减少硬解析流程,提升效率。
✔P (Parse):解析SQL语句,生成解析树、查询树并保存起来。
✔B (Bind):第一次调用则生成并保存计划,若已有计划则直接使用,并将必要的入参补充完整。
✔E (Execute):根据计划执行。
• 对于以PBE方式执行的查询语句和DML语句,优化器会基于规则、代价、参数等因素选择生成 Custom Plan 或 Generic Plan 执行。
✔前 n 次执行时,每次都是硬解析,每一次都产生新的执行计划,叫做 custom plan;
✔当第 n+1 次开始执行时,会生成一个通用的执行计划(generic plan),同时与之前的 custom plan进行比较,如果 generic plan 效率高,则会把执行计划固定下来,此后即使传入的值发生变化,执行计划也不再变化。
• 使用 hint 可以使此类语句强制选择 Custom Plan 或 Generic Plan 。
—3.7 指定 custom plan
语法
use_cplan
✔ 对于非PBE方式执行的SQL语句,设置本hint不会影响执行方式。
—3.8 指定generic plan
语法
use_gplan
✔ 对于非PBE方式执行的SQL语句,设置本hint不会影响执行方式。
—3.9 指定子查询不扩展
语法
no_expand
✔ 数据库在对查询进行逻辑优化时通常会将可以提升的子查询提升到上层来避免嵌套执行 ,通过此 hint 可以使子查询不扩展。
✔ 大多数情况下不建议使用此hint。
4 操作示例
/* ***************************************************** 以下命令为 linux 命令 ************************************************** */
--- su 命令切换到数据库用户 gbase,如果当前用户已为 gbase 用户,则忽略此条命令。
--- linux 命令:gsql 使用默认端口 连接数据库
/* ****************************************************** 以下都为sql命令 ******************************************************* */
--- gsql 连接成功后,将以下 sql 逐条在gsql中执行,进行验证。(若使用dbeaver工具,dbeaver 连接成功后,复制粘贴以下sql 执行进行验证)
/*************************************************/
/***** 1. 指定join方式 ******/
/*************************************************/
insert into t1 select generate_series(1,100),generate_series(1,100);
insert into t2 select generate_series(1,100),generate_series(1,100);
insert into t3 select generate_series(1,100),generate_series(1,100);
explain select * from t1,t2 where t1.id1 = t2.id2;
--- 4. 开启 nestloop,使用 hint 指定执行计划的 join 方式为 nestloop
set enable_nestloop = on ;
explain select /*+ nestloop(t1 t2)*/ * from t1,t2 where t1.id1 = t2.id2;
/*************************************************/
/***** 2. 指定join顺序 ******/
/*************************************************/
--- 1. 使用 3 表查询,查看默认的执行计划
explain select * from t1,t2,t3;
explain select /*+ leading(t1 (t2 t3)) */ * from t1,t2,t3;
/*************************************************/
/*************************************************/
--- 1. 使用 2 表关联,查询默认的中间结果集行数
explain select * from t1,t2;
explain select /*+ rows(t1 t2 #5) */ * from t1,t2;
/*************************************************/
/*************************************************/
--- 1. 使用2表关联,查看默认的数据扫描方式
explain select * from t1,t2 where t1.id1 = t2.id2;
create index t1_id1_inx on t1 using btree (id1);
explain select /*+ indexscan(t1 t1_id1_inx) */ *
from t1,t2 where t1.id1 = t2.id2;
explain select /*+ no indexscan(t1 t1_id1_inx) */ *
from t1,t2 where t1.id1 = t2.id2;
/*************************************************/
/*************************************************/
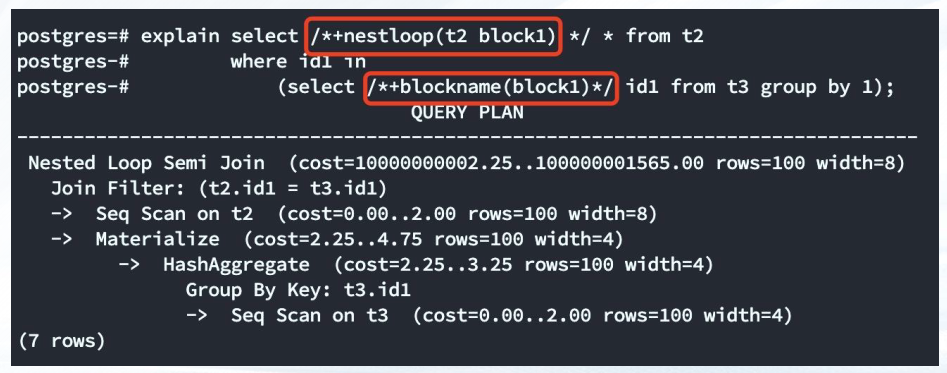
explain select /*+nestloop(t2 block1) */ * from t2
(select /*+blockname(block1)*/ id1 from t3 group by 1);
/*************************************************/
/***** 6. 指定custom plan ******/
/*************************************************/
--- 1. 使用 prepare 创建一个带入参的等值查询语句,并使用Hint指定使用 custom plan
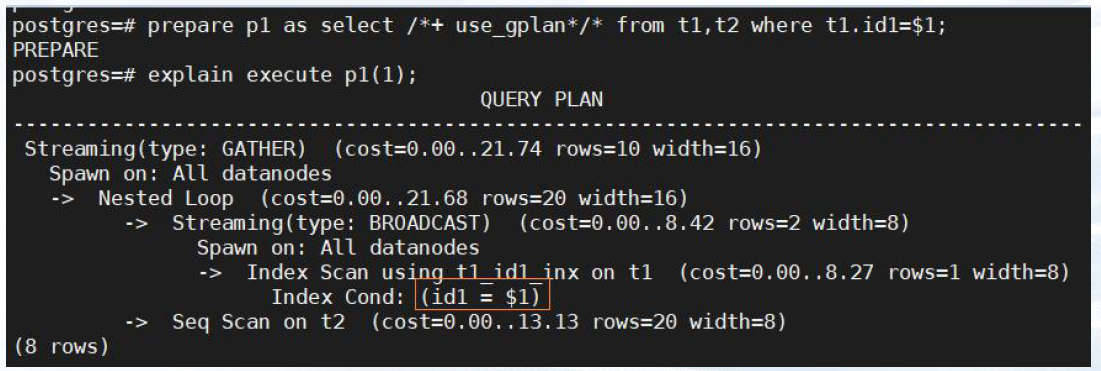
prepare p1 as select /*+ use_cplan */ * from t1,t2 where t1.id1 = $1;
/*************************************************/
/***** 7. 指定generic plan ******/
/*************************************************/
--- 1. 使用 prepare 创建一个带入参的等值查询语句,并使用Hint指定使用generic plan
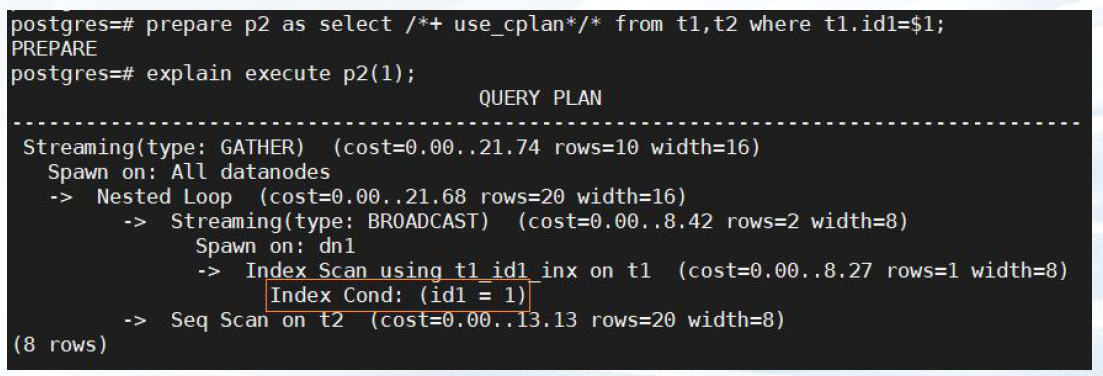
prepare p2 as select /*+ use_gplan */ * from t1,t2 where t1.id1 = $1;
/*************************************************/
/***** 8. 指定子查询不扩展 ******/
/*************************************************/
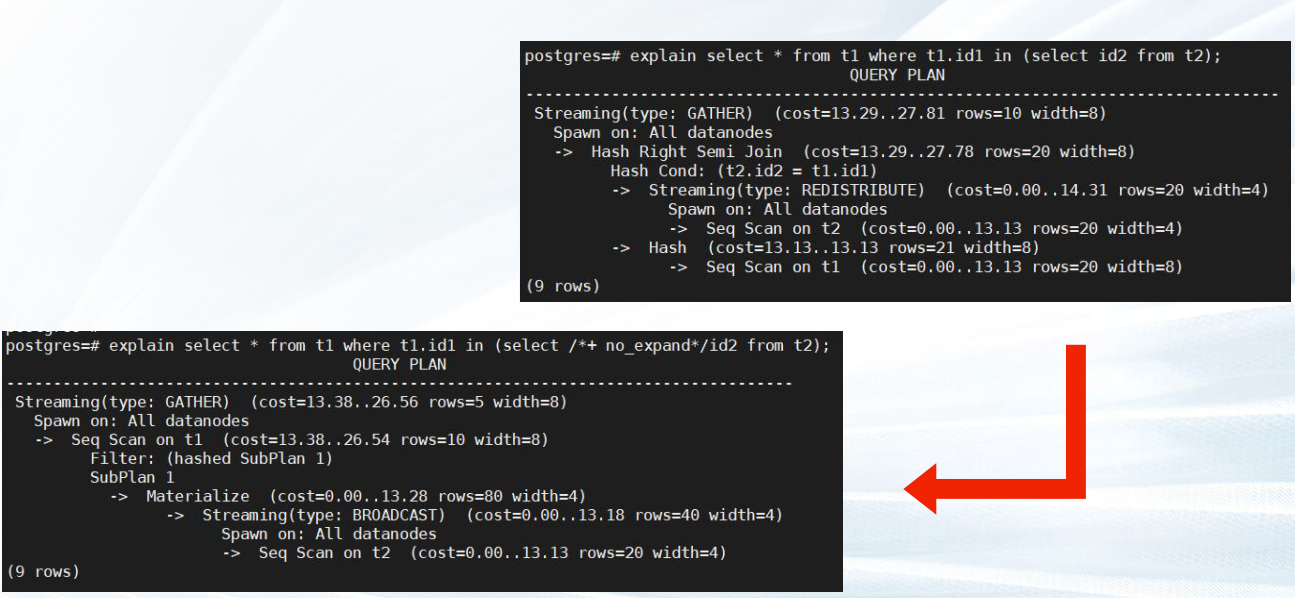
explain select * from t1 where t1.id1 in (select id2 from t2);
explain select * from t1 where t1.id1 in (select /*+ no_expand */ id2 from t2);
/* ***************************************************** 以下命令为 linux 命令 ************************************************** */
--- su 命令切换到数据库用户 gbase,如果当前用户已为 gbase 用户,则忽略此条命令。
su - gbase
--- linux 命令:gsql 使用默认端口 连接数据库
gsql -d postgres -p 5432
/* ****************************************************** 以下都为sql命令 ******************************************************* */
--- gsql 连接成功后,将以下 sql 逐条在gsql中执行,进行验证。(若使用dbeaver工具,dbeaver 连接成功后,复制粘贴以下sql 执行进行验证)
/*************************************************/
/***** 1. 指定join方式 ******/
/*************************************************/
--- 1. 创建示例表
-- 创建表t1
drop table if exists t1;
create table t1 (
id1 int,
id2 int
) ;
-- 创建表t2
drop table if exists t2;
create table t2 (
id1 int,
id2 int
);
-- 创建表t3
drop table if exists t3;
create table t3 (
id1 int,
id2 int
);
--- 2. 插入数据
insert into t1 select generate_series(1,100),generate_series(1,100);
insert into t2 select generate_series(1,100),generate_series(1,100);
insert into t3 select generate_series(1,100),generate_series(1,100);
--- 3. 查看默认执行计划的 join 方式
explain select * from t1,t2 where t1.id1 = t2.id2;
--- 4. 开启 nestloop,使用 hint 指定执行计划的 join 方式为 nestloop
set enable_nestloop = on ;
explain select /*+ nestloop(t1 t2)*/ * from t1,t2 where t1.id1 = t2.id2;
/*************************************************/
/***** 2. 指定join顺序 ******/
/*************************************************/
--- 1. 使用 3 表查询,查看默认的执行计划
explain select * from t1,t2,t3;
--- 2. 使用Hint指定join顺序
explain select /*+ leading(t1 (t2 t3)) */ * from t1,t2,t3;
/*************************************************/
/***** 3. 指定行数 ******/
/*************************************************/
--- 1. 使用 2 表关联,查询默认的中间结果集行数
explain select * from t1,t2;
--- 2. 使用Hint指定行数为5
explain select /*+ rows(t1 t2 #5) */ * from t1,t2;
/*************************************************/
/***** 4. 指定扫描方式 ******/
/*************************************************/
--- 1. 使用2表关联,查看默认的数据扫描方式
explain select * from t1,t2 where t1.id1 = t2.id2;
--- 2. 为 t1 表创建索引
create index t1_id1_inx on t1 using btree (id1);
--- 3. 使用Hint指定使用索引扫描
explain select /*+ indexscan(t1 t1_id1_inx) */ *
from t1,t2 where t1.id1 = t2.id2;
--- 4. 使用 no 指定不走索引扫描
explain select /*+ no indexscan(t1 t1_id1_inx) */ *
from t1,t2 where t1.id1 = t2.id2;
/*************************************************/
/***** 5. 指定子链接块名 *****/
/*************************************************/
--- 1. 使用Hint为链接名指定名称
explain select /*+nestloop(t2 block1) */ * from t2
where id1 in
(select /*+blockname(block1)*/ id1 from t3 group by 1);
/*************************************************/
/***** 6. 指定custom plan ******/
/*************************************************/
--- 1. 使用 prepare 创建一个带入参的等值查询语句,并使用Hint指定使用 custom plan
prepare p1 as select /*+ use_cplan */ * from t1,t2 where t1.id1 = $1;
--- 2. 查看该语句的执行计划
explain execute p1(1);
/*************************************************/
/***** 7. 指定generic plan ******/
/*************************************************/
--- 1. 使用 prepare 创建一个带入参的等值查询语句,并使用Hint指定使用generic plan
prepare p2 as select /*+ use_gplan */ * from t1,t2 where t1.id1 = $1;
--- 2. 查看该语句的执行计划
explain execute p2(1);
/*************************************************/
/***** 8. 指定子查询不扩展 ******/
/*************************************************/
--- 1. 使用子查询,查看默认的执行计划
explain select * from t1 where t1.id1 in (select id2 from t2);
--- 2. 使用Hint指定子查询不扩展
explain select * from t1 where t1.id1 in (select /*+ no_expand */ id2 from t2);
/* ***************************************************** 以下命令为 linux 命令 ************************************************** */
--- su 命令切换到数据库用户 gbase,如果当前用户已为 gbase 用户,则忽略此条命令。
su - gbase
--- linux 命令:gsql 使用默认端口 连接数据库
gsql -d postgres -p 5432
/* ****************************************************** 以下都为sql命令 ******************************************************* */
--- gsql 连接成功后,将以下 sql 逐条在gsql中执行,进行验证。(若使用dbeaver工具,dbeaver 连接成功后,复制粘贴以下sql 执行进行验证)
/*************************************************/
/***** 1. 指定join方式 ******/
/*************************************************/
--- 1. 创建示例表
-- 创建表t1
drop table if exists t1;
create table t1 (
id1 int,
id2 int
) ;
-- 创建表t2
drop table if exists t2;
create table t2 (
id1 int,
id2 int
);
-- 创建表t3
drop table if exists t3;
create table t3 (
id1 int,
id2 int
);
--- 2. 插入数据
insert into t1 select generate_series(1,100),generate_series(1,100);
insert into t2 select generate_series(1,100),generate_series(1,100);
insert into t3 select generate_series(1,100),generate_series(1,100);
--- 3. 查看默认执行计划的 join 方式
explain select * from t1,t2 where t1.id1 = t2.id2;
--- 4. 开启 nestloop,使用 hint 指定执行计划的 join 方式为 nestloop
set enable_nestloop = on ;
explain select /*+ nestloop(t1 t2)*/ * from t1,t2 where t1.id1 = t2.id2;
/*************************************************/
/***** 2. 指定join顺序 ******/
/*************************************************/
--- 1. 使用 3 表查询,查看默认的执行计划
explain select * from t1,t2,t3;
--- 2. 使用Hint指定join顺序
explain select /*+ leading(t1 (t2 t3)) */ * from t1,t2,t3;
/*************************************************/
/***** 3. 指定行数 ******/
/*************************************************/
--- 1. 使用 2 表关联,查询默认的中间结果集行数
explain select * from t1,t2;
--- 2. 使用Hint指定行数为5
explain select /*+ rows(t1 t2 #5) */ * from t1,t2;
/*************************************************/
/***** 4. 指定扫描方式 ******/
/*************************************************/
--- 1. 使用2表关联,查看默认的数据扫描方式
explain select * from t1,t2 where t1.id1 = t2.id2;
--- 2. 为 t1 表创建索引
create index t1_id1_inx on t1 using btree (id1);
--- 3. 使用Hint指定使用索引扫描
explain select /*+ indexscan(t1 t1_id1_inx) */ *
from t1,t2 where t1.id1 = t2.id2;
--- 4. 使用 no 指定不走索引扫描
explain select /*+ no indexscan(t1 t1_id1_inx) */ *
from t1,t2 where t1.id1 = t2.id2;
/*************************************************/
/***** 5. 指定子链接块名 *****/
/*************************************************/
--- 1. 使用Hint为链接名指定名称
explain select /*+nestloop(t2 block1) */ * from t2
where id1 in
(select /*+blockname(block1)*/ id1 from t3 group by 1);
/*************************************************/
/***** 6. 指定custom plan ******/
/*************************************************/
--- 1. 使用 prepare 创建一个带入参的等值查询语句,并使用Hint指定使用 custom plan
prepare p1 as select /*+ use_cplan */ * from t1,t2 where t1.id1 = $1;
--- 2. 查看该语句的执行计划
explain execute p1(1);
/*************************************************/
/***** 7. 指定generic plan ******/
/*************************************************/
--- 1. 使用 prepare 创建一个带入参的等值查询语句,并使用Hint指定使用generic plan
prepare p2 as select /*+ use_gplan */ * from t1,t2 where t1.id1 = $1;
--- 2. 查看该语句的执行计划
explain execute p2(1);
/*************************************************/
/***** 8. 指定子查询不扩展 ******/
/*************************************************/
--- 1. 使用子查询,查看默认的执行计划
explain select * from t1 where t1.id1 in (select id2 from t2);
--- 2. 使用Hint指定子查询不扩展
explain select * from t1 where t1.id1 in (select /*+ no_expand */ id2 from t2);