1 简介
DQL:Data Query Language 数据库查询语言
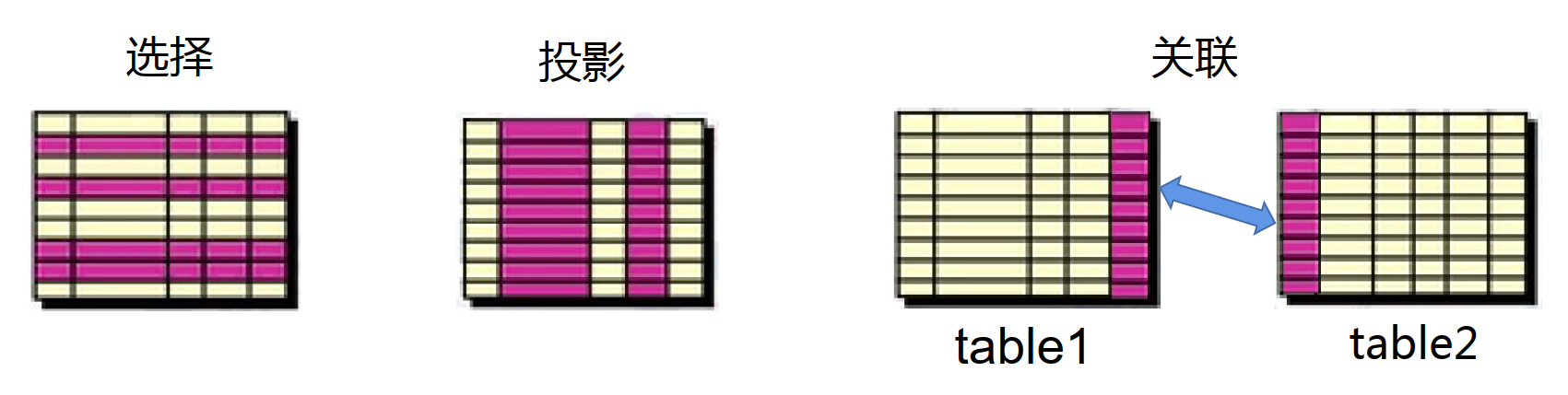
2 SELECT语句语法格式
• 在SQL中,SELECT语句的语法格式为:
SELECT [ ALL | DISTINCT ] <列表达式>, ......
FROM <表名>, ......
[ WHERE <条件表达式> ]
[ GROUP BY <列名>, ...... [ HAVING <条件表达式> ] ]
[ ORDER BY <列名> [ ASC | DESC ], ...... ]
[LIMIT {[offset,] row_count | row_count OFFSET offset}] [INTO OUTFILE ‘file_name’ <导出选项> ] ;
3 编写和执行顺序

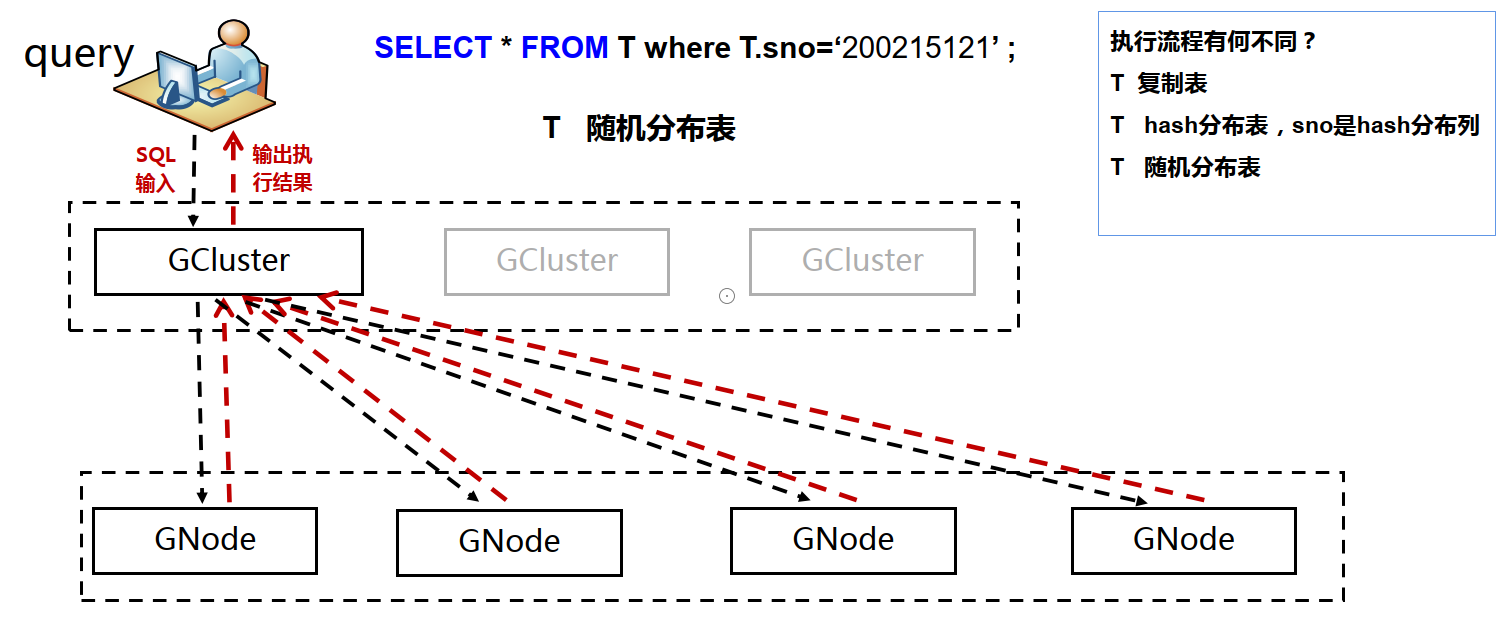
4 DQL执行逻辑
5 单表查询
【示例1】:查询所有学生信息
SELECT * FROM STUDENT ;
* 代表所有列,慎用
【示例2】:查询学生学号和姓名信息。
SELECT Sno, Sname FROM STUDENT;
推荐写具体投影列
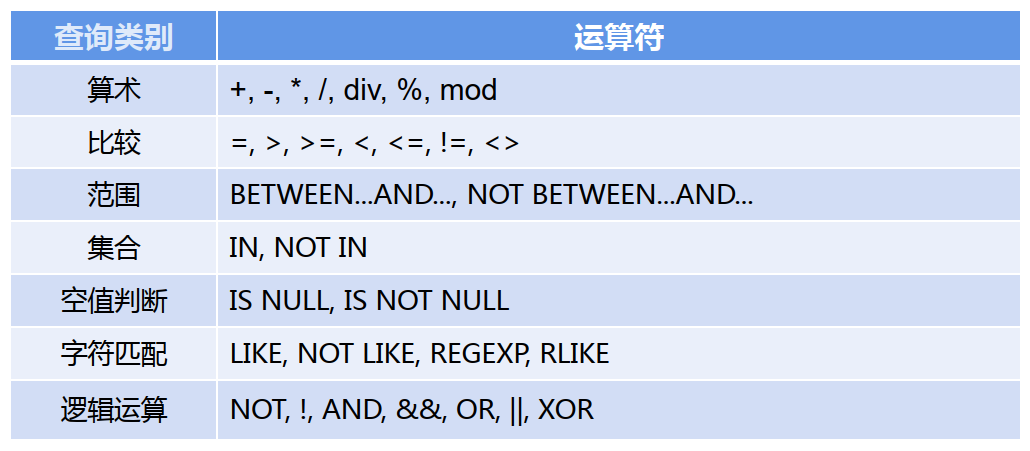
【示例3】:查询偶数年龄的学生学号和姓名。
SELECT Sno 学号,Sname 姓名 FROM STUDENT where Sage % 2 = 0;
推荐写where条件过滤数据
【示例4】:查询年龄19到21岁的学生学号和姓名。
SELECT Sno, Sname FROM Student WHERE Sage BETWEEN 19 AND 21;
BETWEEN... AND范围 等同于>= and <=
【示例5】:查询姓张且全名为2个汉字的学生及姓刘的学生的信息。
SELECT * FROM Student WHERE Sname LIKE '刘%' OR Sname LIKE '张_';
%代表任意多个字符 _代表任意一个字符
【示例6】:查询缺少学生年龄的学生编号。
SELECT * FROM Student WHERE sage IS NULL ;
NULL 表示“空值”,没有数据;
不同于数字 0或‘’ 空字符串;
不能用=号,不能与其他值做运算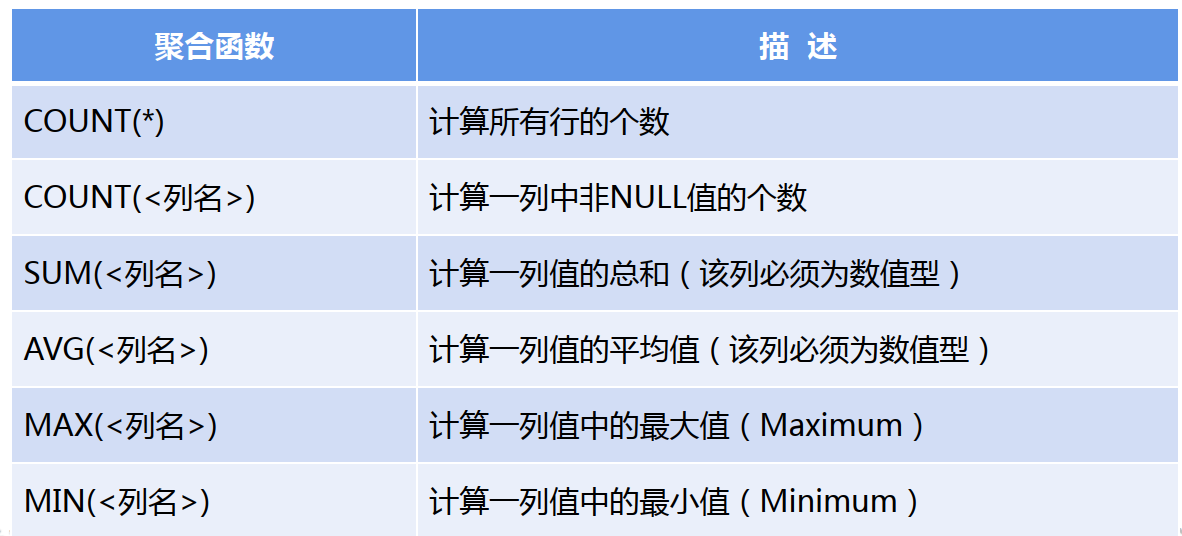
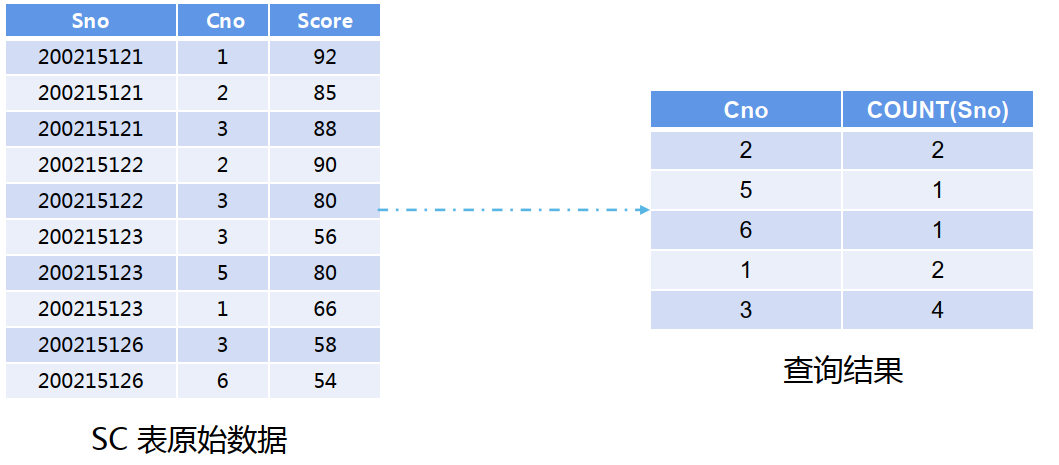
【示例7】:按课程号(Cno)分组,查询每门课程的选课人数
SELECT Cno,COUNT(Sno) FROM SC GROUP BY Cno ;
SELECT 的投影列必须包含在 GROUPBY 中
单表查询
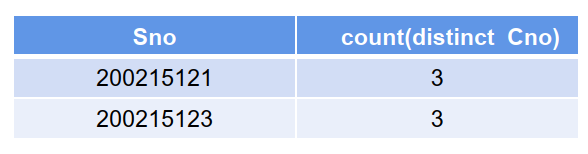
【示例8】:查询选修了2门以上课程的学生学号
SELECT Sno, count(distinct cno) FROM SC GROUP BY Sno HAVING COUNT(*)>2
ORDER BY sno;
having是分组聚合运算后的结果上进行筛选
where、having 的区别和用法 :
1、where 后不能跟聚合函数,因为where执行顺序在分组前过滤数据。
2、 having 子句的作用是筛选满足条件的组,即在分组之后过滤数据, 条件中经常包含聚合函数。
【示例9】:按学生年龄降序排名
SELECT * FROM Student ORDER BY sage DESC ;
【示例10】:查询年龄最大的前三名学生信息
SELECT * FROM Student ORDER BY sage DESC LIMIT 3;
LIMIT 3; //检索前 3个记录行
LIMIT 3,10; // 检索记录行 4-13
LIMIT 10 OFFSET 3; // 检索记录行 4-13
【示例11】:使用LIMIT 实现显示11-20条结果集
SELECT * FROM Student ORDER BY sage DESC LIMIT 10,10;
【示例12】:使用LIMIT 实现分页显示
1. select * from studnet limit (pageNumber-1)*pageSize, pageSize;
2. select * from student limit pageSize offset (pageNumber-1)*pageSize;
6 表关联查询
—6.1 连接查询
——6.1.1 介绍
• 若一个查询同时涉及两个及以上的表,则需要连接查询
• 关系数据库的强大处理能力正是源于各种形式的连接查询,能够将不同表的数据按一定条件连接在一起
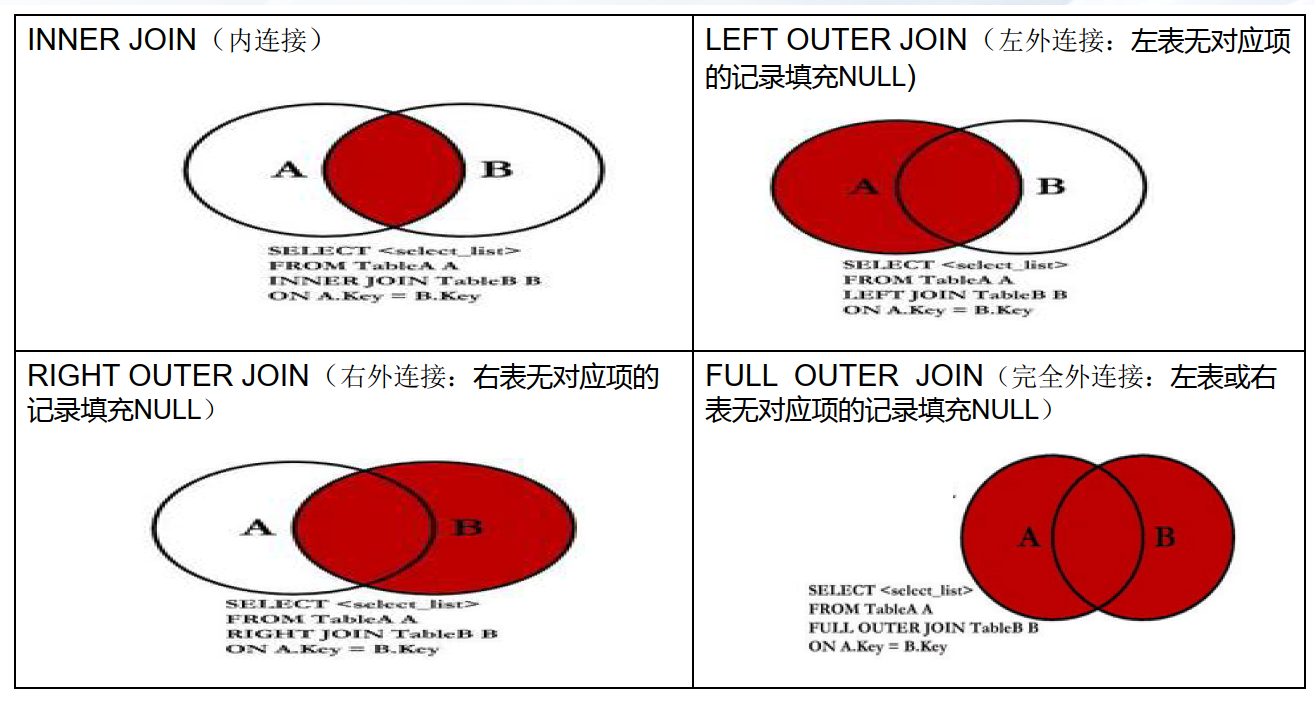
• SQL 提供的链接查询分为内连接(Inner Join)和外连接(Outer Join)两大类型
− 内连接将两个表连接在一起的条件称为连接谓词(Join Predicate)或连接条件
− 内连接只返回两个表中与连接谓词匹配的行,不匹配的行不会被输出
− 外连接可以将左表或右表中不匹配的行输出
− 外连接分为左外连接(Left Outer Join)、右外连接(Right Outer Join)和完全外连接(Full Outer Join)
——6.1.2 笛卡尔积
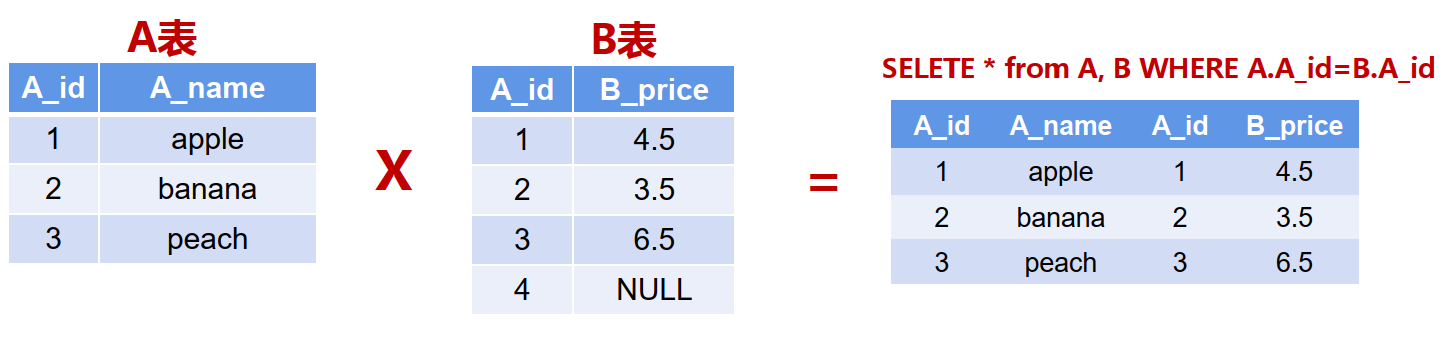
• 在编写中,避免出现笛卡尔积,会导致性能很差
• 只要有意义的结果,增加关联条件
WHERE A.A_id = B.A_id;
——6.1.3 内连接
SELECT <列名>, ......
FROM <左表>,<右表>
WHERE <左表>.<主键> <比较运算符> <右表>.<外键>
或
SELECT <列名>, ......
FROM <左表> INNER JOIN <右表>
ON <左表>.<主键> <比较运算符> <右表>.<外键>
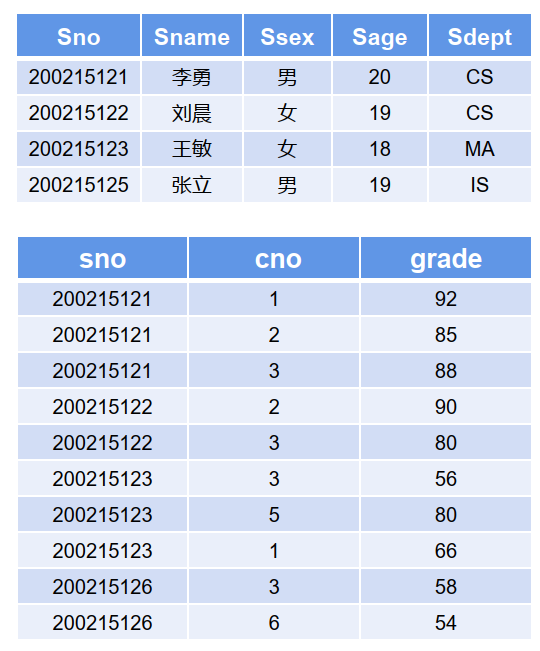
示例:
【示例】:查询每个学生及其选修课程的情况
写法一:SELECT S.Sname, S.Ssex, SC.Cno, SC.GRADE FROM Student S, SC WHERE S.Sno=SC.Sno;
内连接,结果集取两表中符 合条件的记录
写法二: SELECT S.Sname, S.Ssex, SC.Cno, SC.GRADE FROM Student S INNER JOIN SC ON S.Sno=SC.Sno;
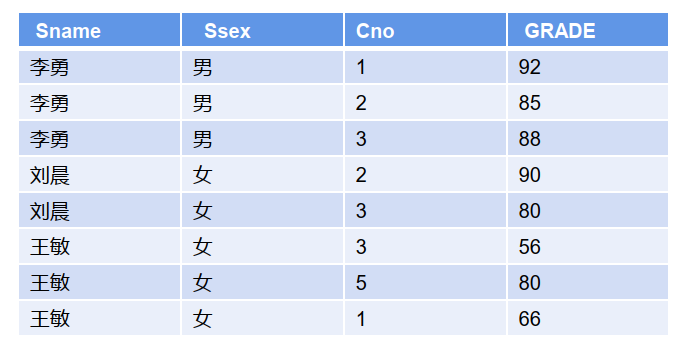
——6.1.4 左外连接
【示例】:查询每个学生及其选修课程的情况(包括未选课学生)
左外连接: SELECT S.Sno, S.Sname, S.Ssex, S.Sage, S.Sdept, SC.Cno, SC.GRADE
FROM Student S LEFT OUTER JOIN SC ON S.Sno=SC.Sno ;
左外连接,结果集取左表中全部的行, 如右表中没有符合条件的对应则填充null
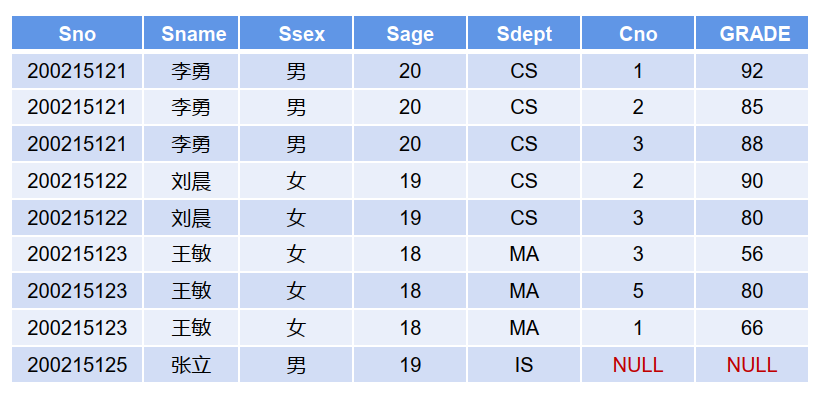
——6.1.5 左右连接
【示例】:查询每个学生及其选修课程的情况(包括未选课学生)
右外连接: SELECT S.Sno, S.Sname, S.Ssex, S.Sage, S.Sdept, SC.Cno, SC.GRADE
FROM Student S RIGHT OUTER JOIN SC ON S.Sno=SC.Sno ;
右外连接,结果集取右表中 全部的行,如左表中没有符 合条件的对应则填充null
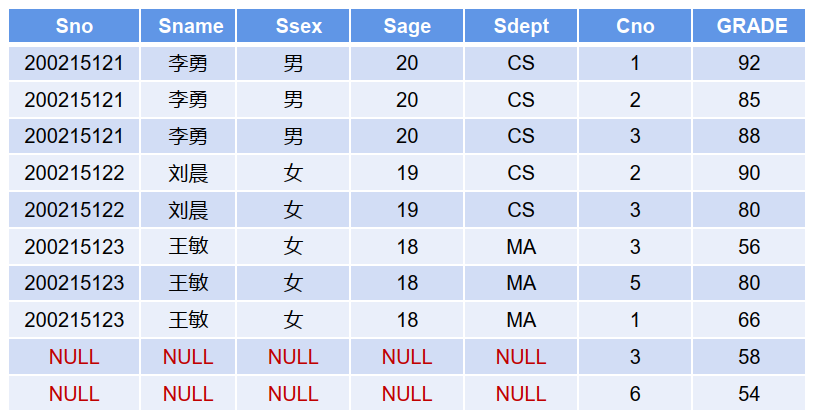
——6.1.6 全连接
【示例】:查询每个学生及其选修课程的情况
全连接: SELECT S.Sno, S.Sname, S.Ssex, S.Sage, S.Sdept, SC.Cno, SC.GRADE
FROM Student S FULL OUTER JOIN SC ON S.Sno=SC.Sno ;
全连接,结果集取两张表中全部的行, 如没有符合条件的对应项则填充null
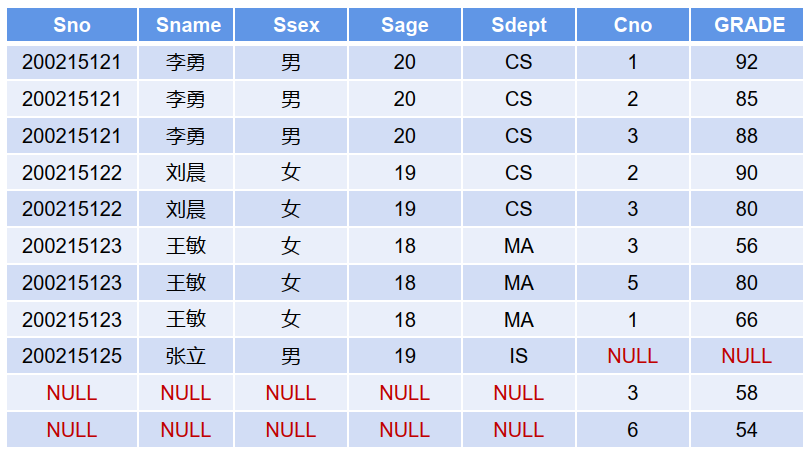
全连接
SELECT S.Sno, S.Sname, S.Ssex, S.Sage, S.Sdept, SC.Cno, SC.GRADE
FROM Student S FULL OUTER JOIN SC ON S.Sno=SC.Sno ;
等价于左外连接 UNION 右外连接
SELECT S.*, SC.Cno, SC.GRADE FROM Student S LEFT OUTER JOIN SC
ON S.Sno=SC.Sno
UNION
SELECT S.*, SC.Cno, SC.GRADE FROM Student S RIGHT OUTER JOIN SC
ON S.Sno=SC.Sno ;
注:实际编写SQL中,尽量少用全连接,避免结果集过大导致性能慢。
——6.1.7 自连接
是连接的一种用法, 本质是把一张表当成两张表来使用,一般用别名区分。
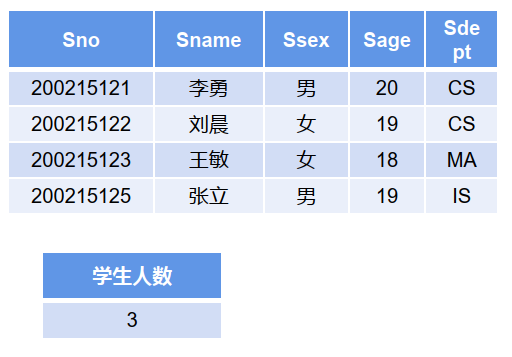
【示例】:查询比 '王敏’年龄大的学生的人数( 在Student表中,’王敏’的年龄为18)
分步方式:
SELECT sage FROM student WHERE sname='王敏'; //得出sage查询结果为18
SELECT count(*) 学生人数 FROM student WHERE sage>18;
自连接方式(在一条 SQL 中实现):
SELECT count(*) 学生人数
from student as a, student as b
where a.sname='王敏' and a.sage<b.sage;
a和b是student表的别名
——6.1.8 多表连接
【示例】:查询每个学生学号,姓名,选修的课程名及成绩
SELECT S.Sno, S.Sname, C.Cname, SC.Grade FROM Student S ,Course C,SC
WHERE S.Sno=SC.Sno AND SC.Cno=C.Cno ;
两个以上的表进行连接,这称为多表连接。
说明:
− 多表关联时,基于代价进行优化,内关联跟表书写顺序无关;
− where条件从右向左顺序执行,建议把返回结果集小的表条件写到最后; − 使用explain … 在线查询 SELECT 语句执行计划
7 UNION集合查询
—7.1 Union 和 Union All
应用:如果两个或多个 SELECT 语句的结构相似,则可以用“Union”或“Union All”把这些 SELECT 语句合并起来
UNION 与 UNION ALL 的区别:
● UNION : 对两个结果集进行并集操作,不包括重复行;
● Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
● 如果结果集没重复数据,建议使用Union All 代替UNION,性能更好。
注意:保证各个select 集合的结果有相同个数的列,并且每个列的类型是一样的。
1. 两端都是char类型数据,会隐式转换成varchar类型。
2. 小的数据类型向大的数据类型转换,如:INT -> BIGINT -> DECIMAL -> DOUBLE

8 总结
编写高效SQL语句
1.避免生产环境使用select *,减少投影列
2.数据量大时,group By 、order by会很费时,建议将hash分布列写在第一个位置
3.使用where条件提前过滤数据,减少join的运算
4.使用limit 减少物化的结果集条数
5.在做多表查询时应注意字段名称的唯一性;如果不唯一,则要明确写明表名。
6.内连接比外连接效率要高,连接查询所使用的字段最好是hash分布键。
7.注意笛卡尔积的问题:
关注 /opt/gnode/tmpdata/cache_gbase/HashJoin 空间变化,如果出现2-10G增长,则 表示可能出现笛卡尔积