- 1 DDL综述
- 2 数据库管理
- —2.1 DDL数据库DATABASE
- —2.2 DATABASE操作语法
- 3 表的管理
- —3.1 表TABLE
- —3.2 数据模型设计
- —3.3 数据分布演示
- —3.4 数据分布策略:哈希分布的确定性 vs 随机分布的均匀性
- —3.5 创建表操作语法
- —3.6 分布表
- —3.7 hash分布表—distributed by列对数据分布的影响
- —3.8 hash分布数据均匀—分布列选择最重要
- —3.9 复制表
- —3.10 操作语法
- ——3.10.1 表类型
- ——3.10.2 临时表
- ——3.10.3 表复制操作语法
- ——3.10.4 修改表操作语法
- ——3.10.5 字段类型的修改方法
- ——3.10.6 修改压缩方式
- ——3.10.7 预租磁盘
- ——3.10.8 其他表操作语法
- 4 视图VIEW管理
- —4.1 介绍
- —4.2 视图操作语法
- —4.3 表和视图查看操作语法
- 5 索引管理
- —5.1 索引概述
- —5.2 hash索引
- —5.3 Hash 索引操作语法
- —5.4 Hash 索引操作示例
1 DDL综述
DDL(Data Definition Language)
− 数据库定义语言,用于定义和管理数据库中的所有对象的SQL语言。
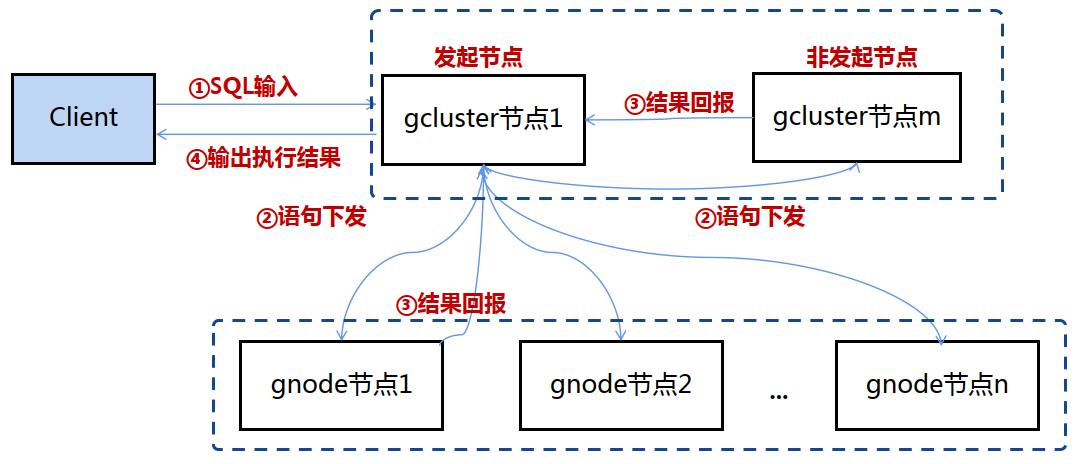
− DDL操作影响数据库对象的元数据信息,一条DDL命令会在所有gcluster管理节点和gnode计算节点执行,所有节点保存元数据信息。
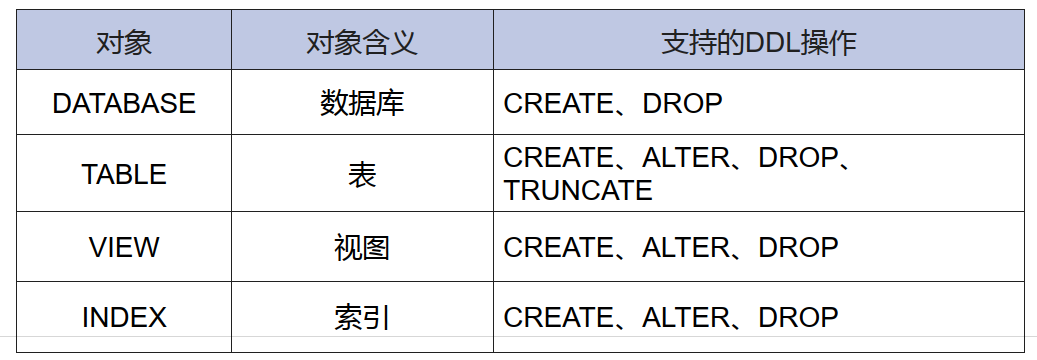
执行逻辑:
发起管理节点会将DDL命令下发给gcluster管理节点和gnode计算节点,各节点更新元数据、更新系统表, 然后返回结果给发起管理节点。
2 数据库管理
—2.1 DDL数据库DATABASE
数据库(database)
• 按照一定的数据结构来组织、存储和管理数据的仓库。
• 数据库含有各种成分,包括表、视图、存储过程、自定义函数、索引等
• 一个GBase 8a MPP系统中,可以有一个或多个数据库
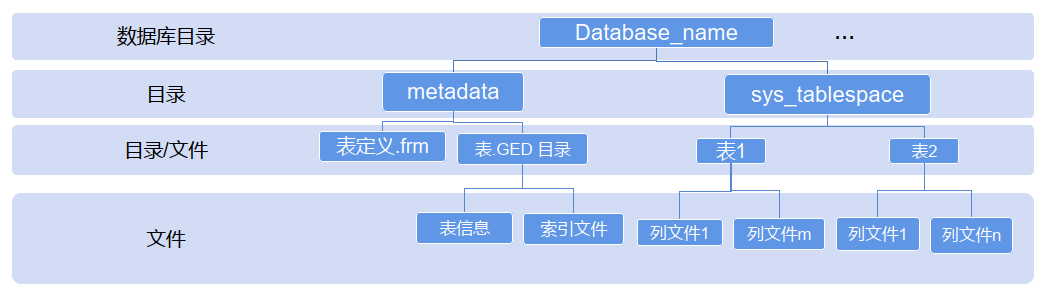
• 数据库物理存储是目录,保存在系统参数datadir指定目录下面
• 数据库目录包括metadata(元数据)和sys_tablespace(默认表空间)子目录
• gnode节点的sys_tablespace目录下存放具体的列数据文件。
—2.2 DATABASE操作语法
创建数据库 CREATE DATABASE [IF NOT EXISTS] database_name; 示例:CREATE DATABASE if not exists test; 删除数据库 DROP DATABASE [IF EXISTS] database_name; 指定当前数据库 USE database_name; 查询现有数据库 show databases; 查询当前数据库 select database(); 备注: DROP DATABASE 删除指定的数据库以及它所包含的表。生产环境禁止使用drop语句! 用户需要获得对数据库的 DROP 权限,才可以使用 DROP DATABASE。
3 表的管理
—3.1 表TABLE
表是关系型数据库中储存数据的基本架构。表的管理包括创建表、表拷贝、修改表、清 空表、删除表。
在gbase 8a MPP系统中,表对外为一个整体,内部以表分片在各节点以列文件形式分 布存储。
表数据有以下性质:
• 每一列中的数据都是同类型的数据。
• 不同列有不同的属性名。
• 列是无序的,左右顺序无关。
• 行的次序可以变换,跟顺序无关。
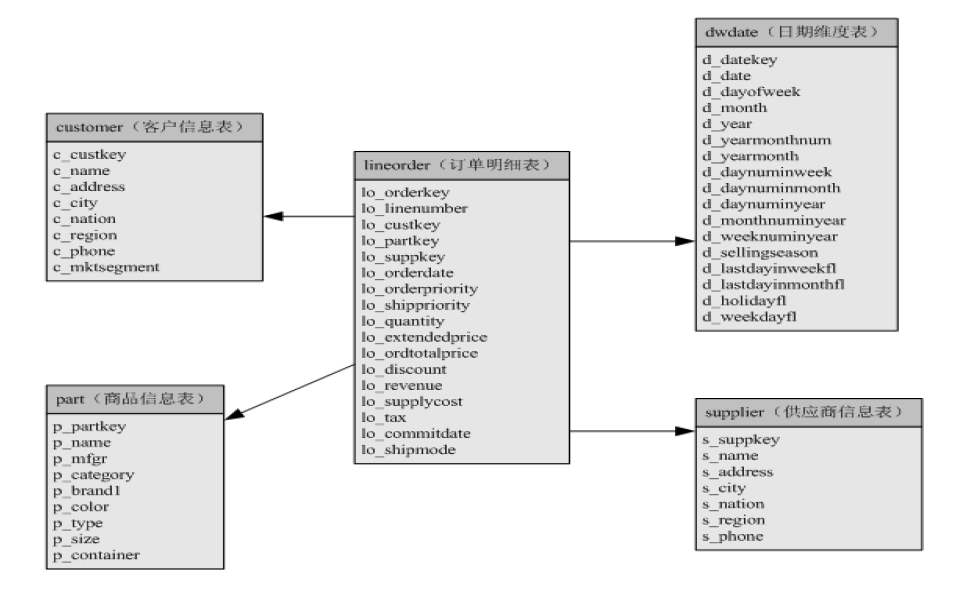
—3.2 数据模型设计
GBase 8a集群中,包含如下表类型:
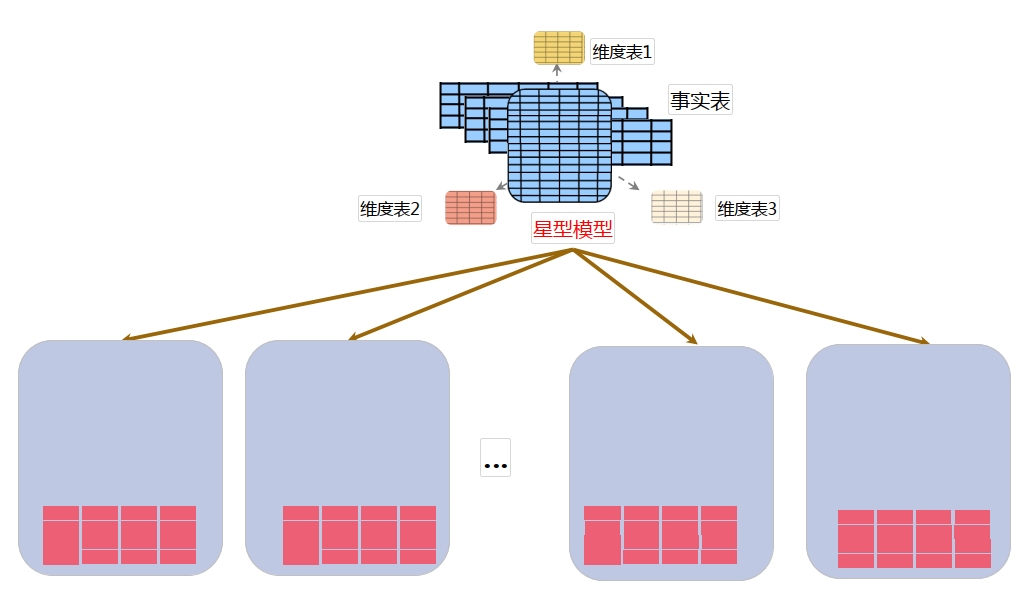
GBase 8a集群适用的数据模型包括:
• 星型
• 雪花型
数据模型设计原则:
• 大表建成分布表,推荐建成hash分布表
• 小表建成复制表
• 频繁跟其他表做等值join连接 的表(如维度表)建成复制表
—3.3 数据分布演示
数据灵活分布
本地存储
并行计算
—3.4 数据分布策略:哈希分布的确定性 vs 随机分布的均匀性
—3.5 创建表操作语法
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [database_name.]table_name (column_definition [,column_definition], ... ) [table_options]
参数说明:
列定义:列名称 数据类型 [NOT NULL | NULL] [DEFAULT default_value] [COMPRESS (数值)] [COMMENT]
表选项:[REPLICATED | DISTRIBUTED BY ('column_name') ] [COMPRESS(数值型,字符型)] [COMMENT ]
DEFAULT:指定数据列的默认值。默认值必须是一个常数,不能是一个函数或者一个表达式。
COMMENT:指定数据列或表的备注说明。用法:comment '备注信息' 。可以使用 SHOW CREATE TABLE table_name 和 SHOW FULL COLUMNS FROM table_name 语句来显示备注信息。
COMPRESS:指定相关数据类型的压缩方式。数值型:0,1,5;字符型:0,3,5;0:不压缩;1:对数值型进行深度压缩;3:对字符型进行深度压缩;5:轻度压缩;表压缩组合(0,0)、深度压缩(1,3)、轻度压缩(5,5)
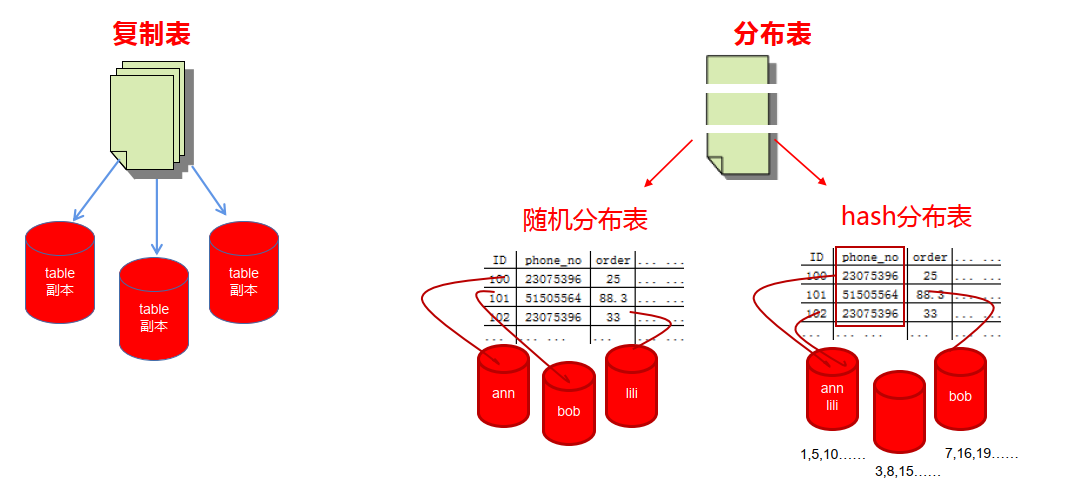
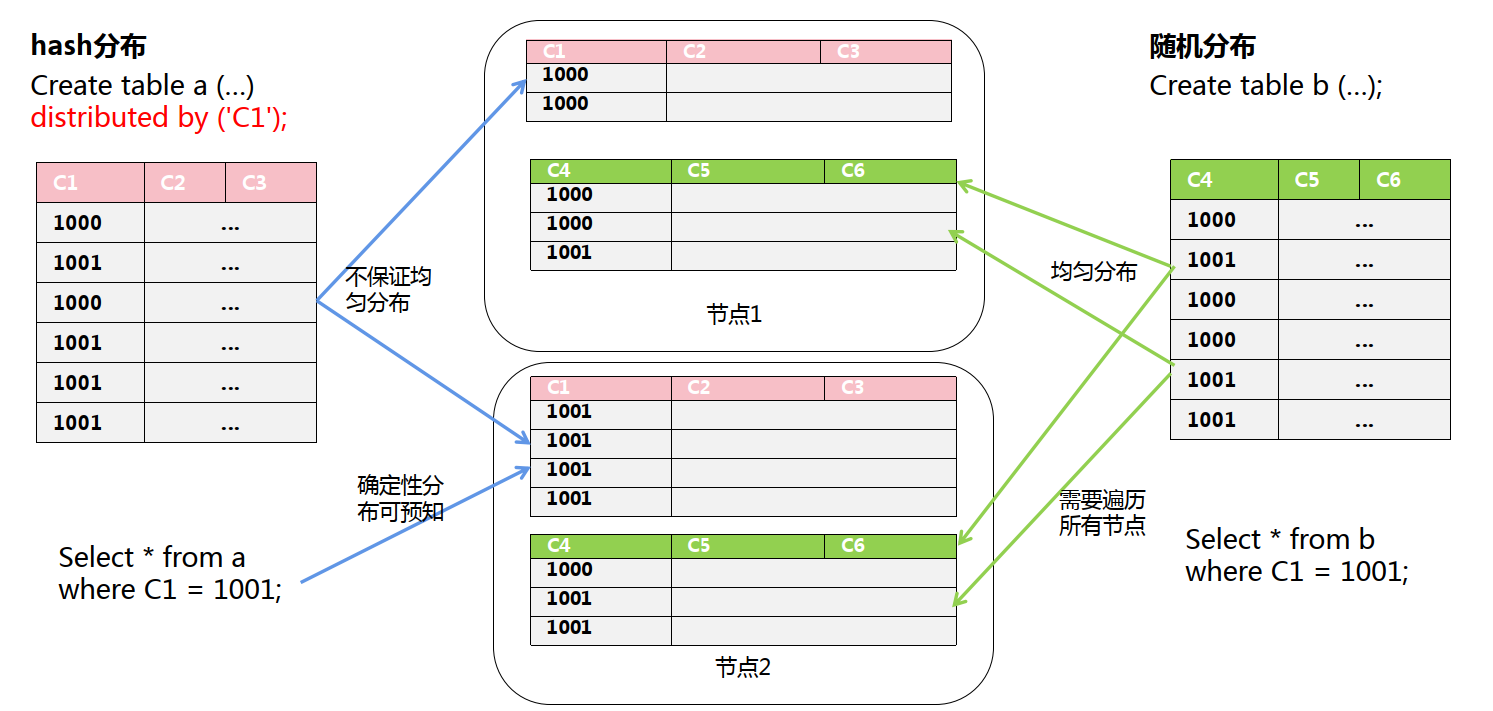
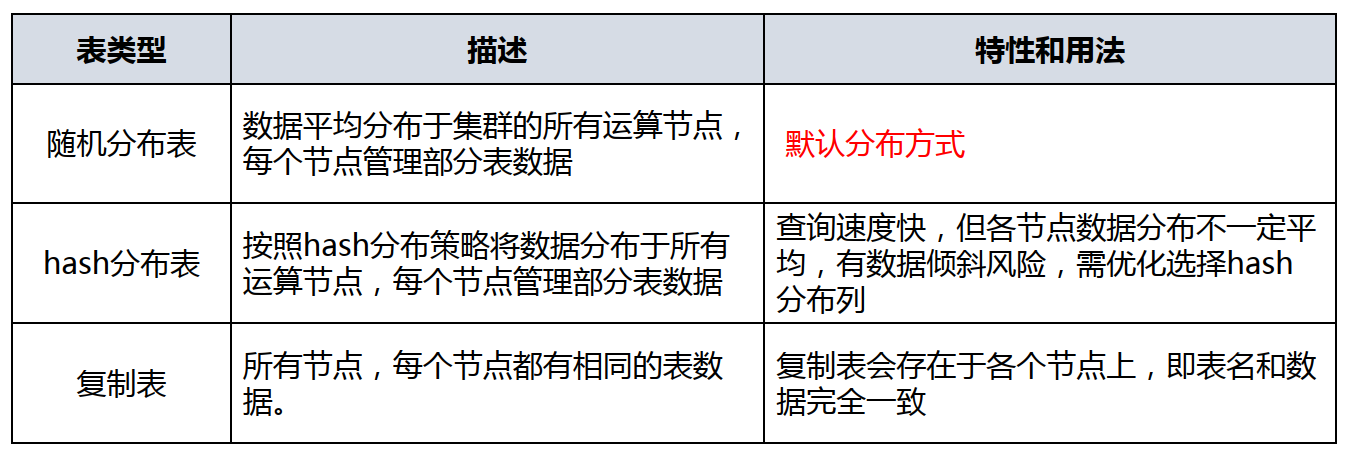
—3.6 分布表
● 分布表可以使数据按指定的策略分布存储在不同的主机上,从而实现分布式数据存储和分布式计算,解决大数据存储容量扩展和计算性能扩展的问题。
● 分布策略:采用hash分布、random分布策略存储数据
● 默认创建的表是随机分布表,每个节点上只保留部分表数据。
● Hash分布表能实现相同数据在同一节点上,实现本地化运算,推荐大表建成hash分布表。
举例—随机分布表:
CREATE TABLE t1(a int , b varchar(10), KEY a_key (a) USING HASH GLOBAL);
举例—hash分布表:
CREATE TABLE student
(stu_no varchar(10), stu_name varchar(200),stu_sex int)
DISTRIBUTED BY('stu_no');
—3.7 hash分布表—distributed by列对数据分布的影响
Create table user_info ( stat_date date , user_id varchar(20)) distributed by (‘user_id’) 数据情况:表中数据 1万条,日期stat_date全是20131231,user_id 完全无重复。
− 选择user_id作为分布列,则每个节点上分布的数据基本相同。

− 选择stat_date 作为分布列,因为全是20131231,则所有数据都会落到一个节点上,造成数据倾斜,性能瓶颈,没达到均匀分布、分散计算的目的。
—3.8 hash分布数据均匀—分布列选择最重要
选取distributed by列字段的原则:
• 在多表JOIN查询时,表中某列经常用于JOIN等值关联;
• 表中该列通常是等值查询的列,并且使用的频率很高;
• 做group by操作时,分组字段;
• 表中重复值较少的列,尽量让数据均匀分布。
被选为distributed by列字段,有如下限制说明:
• 当前只支持INT、BIGINT、varchar、decimal数据类型。 • distributed by列的值,不允许进行update操作。
—3.9 复制表
● 复制表将会存在于各个节点上,即表的名字和数据完全一致。 ● 需要使用REPLICATED关键字来创建复制表。
● 复制表不用拉表即可实现本地运算,效率高。
● 一般来说,小表(维度表)可以被创建成复制表。
● 一些表频繁参与JOIN查询表也可以被创建成复制表。
举例:
create table t1(a int) replicated;
—3.10 操作语法
——3.10.1 表类型
——3.10.2 临时表
临时表
使用关键词TEMPORARY,临时表被限制在当前连接中,当连接关闭时,临时表会自动被删除。临时表可以是随机分布表、hash分布表、复制表中的任意一种表类型。
创建临时表:(修改和删除语法和普通表一样)
CREATE TEMPORARY TABLE tem_table (a int);
创建一个hash分布表的临时表,示例:
CREATE TEMPORARY TABLE t1 (a int,b varchar(10)) DISTRIBUTED BY ('a');
注意事项:
− 临时表支持除 ALTER 之外的所有 DDL 及 DML 操作。
− 临时表不能被备份。
− 临时表支持在当前连接中使用查询结果导出语句导出表中数据。
——3.10.3 表复制操作语法
表结构和表数据复制
根据列定义以及投影列创建新的表结构,并将 SELECT查询的数据复制到所创建的新表中。不指定目标表的 类型时,默认创建随机分布表。
语法:
CREATE TABLE table_name [REPLICATED] [DISTRIBUTED BY] [AS] SELECT...;
示例:
create table t2 distributed by ('fx') as select * from t1;
create table t2 replicated as select * from t1;
create table t2 as select * from t1 ;
create table t2 as select * from t1 limit 0;
表结构复制分为两类:
1、根据列定义以及投影列创建新的表结构。...as select...limit 0;
2、只创建表结构,没有数据。目标表和源表的表类型完全一致。...like...
类型1示例:
create table t2 distributed by ('fx') as select * from t1 limit 0; create table t2 replicated as select * from t1 limit 0;
create table t2 as select * from t1 limit 0;
类型2示例:
CREATE TABLE table_name2 LIKE table_name1;
——3.10.4 修改表操作语法
修改表语法:
ALTER TABLE <表名> [ ADD [COLUMN] (新列定义,,...) ] [ CHANGE ( <旧列名> <新列名> <列类型> ,...... ) ]
| MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name ] |
[DROP [COLUMN] ( <列名> ,...... ) ] | RENAME [TO] <新表名> | SHRINK SPACE |ALTER [列名] COMPRESS (值)|;
说明:
ADD [COLUMN] (新列定义,,...):增加新列。
CHANGE ( <旧列名> <新列名> <列类型> ,...... ) :修改列名称。不支持修改列定义。
MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name] :修改表中存在列的位置。不支持修改列定义。
DROP [COLUMN] ( <列名> ,...... ):删除表中存在的列。
RENAME [TO] <新表名>:修改表名称。
SHRINK SPACE :释放被删除的数据文件所占的磁盘空间。
ALTER [列名] COMPRESS(值):修改表或列的压缩方式。
语法示例:
ALTER TABLE t ADD column c varchar(10) null; -- 新增一列,列名为c ALTER TABLE t CHANGE b d varchar(10); -- 修改b列的名字为d ALTER TABLE t MODIFY b varchar(10) FIRST; -- 修改b列字段位置为第一个 ALTER TABLE t MODIFY b varchar(10) AFTER c; -- 修改b列字段位置在c列后面 ALTER TABLE t MODIFY b varchar(100); -- 修改b列的varchar字段最大长度到100字符 ALTER TABLE t DROP column b; -- 删除b列 ALTER TABLE t RENAME t2; -- 修改表t的名字为t2
注意事项:
− 不支持改变列的数据类型、改变列的属性(NOT NULL,默认值)、改变表的字符集;
− varchar类型可改变列的长度,只能变大,不能变小;
——3.10.5 字段类型的修改方法
修改字段类型,不支持直接sql语句进行修改。
可通过如下 6 步修改列的类型:
增加新列->update新列值->移动新列至指定位置->老列重命名->新列重命名->删除老列
示例:修改表中 old 列类型由 float(18,6) 修改成 decimal(26,6)
1、alter table tablename add column new decimal(26,6);
2、update tablename set new = old;
3、alter table tablename modify new decimal(26,6) after old;
4、alter table tablename change old bbb float(18,6);
5、alter table tablename change new old decimal(26,6);
6、alter table tablename drop column bbb;
——3.10.6 修改压缩方式
修改表或列的压缩方式。
示例:
ALTER TABLE t1 ALTER a COMPRESS(1); -- 修改t1表a列的压缩模式为1 ALTER TABLE t2 ALTER COMPRESS(5,5); -- 修改t2表压缩模式为55压缩
注意事项:
压缩模式保存在DC块结构中,压缩模式改变只对后续入库的数据有效;
优先级:列级定义压缩> 表级定义压缩 > 系统参数全局定义压缩方式;
− 数值型(含日期型)数据压缩选项 0、1、5;字符型数据压缩选项0、3、5
− 表的压缩类型可遵循(数值型,字符型)组合:(0, 0)、(1, 3)、(5, 5)......
——3.10.7 预租磁盘
• 预租磁盘空间可以预先批量分配磁盘块,尽量保证列的 DC 数据文件磁盘块连续。在顺序读取列 DC 数据时,有助于性能提升。
• 创建表时,可以指定表的自动扩展大小。当表中的存储数据超过指定的预租大小空间时,系统会自动按照预租磁盘大小空间进行自动扩展。
• 预租磁盘空间大小在[1M,2G)范围内设置,单位 M 或 G
创建预租磁盘空间:
CREATE TABLE [IF NOT EXISTS] table_name (col type,...) AUTOEXTEND ON NEXT NUM[M/G];
注:NUM 的有效范围为 1M ≤ NUM < 2G。
修改预租磁盘空间:
ALTER TABLE table_name AUTOEXTEND ON NEXT NUM[M/G]
关闭预租磁盘空间:
ALTER TABLE table_name AUTOEXTEND OFF
——3.10.8 其他表操作语法
重命名表
RENAME TABLE 原表名 TO新表名;
ALTER TABLE 原表名 RENAME 新表名;
清空表内容
删除表中所有行,但表结构及其列、约束、索引等保持不变。
TRUNCATE TABLE b;
删除表
drop table t1;
注意事项:
− TRUNCATE比DELETE效率高,还能释放物理空间;
− DROP TABLE 移除表的数据和表定义,用户必须有表的 DROP 权限。生产环境慎用此命令!
4 视图VIEW管理
—4.1 介绍
是由SELECT语句组成的查询定义的虚拟表(Virtual Table)。
视图跟表不同,表有实际储存数据,而视图是虚拟表,本身不实际储存数据。
视图就像一个窗口,引用视图时动态生成,数据来自当前或其它数据库的一个或多个表,或者其它视图, 对视图的查询操作跟表相同。
作用:
简单性,简化用户对数据的理解,也简化操作,被经常使用的查询可以被定义为视图。
安全性:通过视图用户只能查询他们所能见到的数据。数据库授权命令可以使每个用户对数据库的检索限 制到特定的数据库对象上。
限制:
禁止对视图进行INSERT、UPDATE 和 DELETE 操作
—4.2 视图操作语法
创建视图:
CREATE [OR REPLACE] VIEW [<视图名> [ ( <列名1>, <列名2>, ...) ] AS SELECT…;
修改视图:
ALTER VIEW <视图名> [ ( <列名1>, <列名2>, ...) ] AS SELECT …;
删除视图:
DROP VIEW [IF EXISTS]<视图名>;
示例:
CREATE OR REPLACE VIEW v_t AS SELECT name, address, sex FROM t;
ALTER VIEW test.v_t(a, b) AS SELECT name, address FROM t;
DROP VIEW if exists v_t;
—4.3 表和视图查看操作语法
命令语法:
SHOW TABLES [FROM DB_NAME] [LIKE 'pattern'];
DESC table_name;
SHOW CREATE TABLE [database_name.]table_name
SHOW CREATE VIEW [database_name.]view_name
示例:
show tables from test like 't%'; -- 显示以t字母开头的表和视图
desc t1; -- 查看t1表的字段信息
SHOW create table t1; -- 查看t1 表的建表语句
Show create view v_t; -- 查看v_t 视图的创建语句
5 索引管理
—5.1 索引概述
• 数据库索引是为了提升查询定位效率而对表字段附加的一种标识,避免全表扫描。
• 索引文件单独存储, GBase 8a 系统索引文件存储在 metadata目录下。
• GBase 8a 系统支持三类索引:
− 智能索引:
粗粒度,在DC满块时自动创建智能索引,所有列都有,对用户透明,无需用户手动维护。
− hash索引:
提升等值查询的性能,需用户根据查询列手动创建,会影响数据入库性能。
− 全文检索:
提升文本内容的查询效率,采用全单字索引方式,并且可以保证 100%的查询召回率,需要用户手动创建,需特别安装支持全文检索的插件包后才能使用全文检索功能。
—5.2 hash索引
• hash索引:提高等值精确查询性能
• 默认创建 GLOBAL 的哈希索引,基于整列数据创建索引。
• 可以基于指定的 DC窗口建立分段索引;
• hash索引文件为独立的文件存储。
• 创建hash索引的语法有2种形式:
CREATE INDEX index_name ON [vc_name.][database_name.]table_name(column_name) [key_block_size = size_value] USING HASH [GLOBAL| key_dc_size=num];
或者通过 ALTER 语法创建索引:
ALTER TABLE [table_name] ADD INDEX index_name(column_name)USING HASH [key_dc_size = num][key_block_size = size_value];
说明:
key_dc_size:设置按 DC窗口大小来建立分段的hash索引文件;
key_block_size :索引数据按页存储,设置每个数据块占用的页大小,4k~32K之间,为4k的倍数;
—5.3 Hash 索引操作语法
● 查看 INDEX 名称:
SHOW INDEX FROM [database_name.]table_name;
● 删除索引的2种语法:
DROP INDEX <索引名> ON <表名> ;
或者:
ALTER TABLE [table_name] DROP INDEX index_name;
• 限制说明
● BLOB、TEXT列不能创建HASH索引
● 该列数据量较大,但distinct 值较少,即重复值较多时,也不适合使用HASH索引。
● 创建索引时,只能指定单列,不能指定多列创建联合索引;
● 创建索引会影响加载性能,需慎用。
—5.4 Hash 索引操作示例
create index idx_t1_a on t1 (a) using hash global;
-- 基于列的全部数据建立索引
alter table t1 ADD INDEX h_index(a) key_block_size=4096 USING hash;
-- 基于列的全部数据建立索引,索引数据页大小为4k
create index idx _t1_c on t1(c) key_dc_size=50 using hash global;
-- 基于指定的 50个DC窗口建立分段hash索引文件
show index from t1;
-- 查看已创建的索引
alter table t1 drop index idx _t1_c;
-- 删除已创建的索引