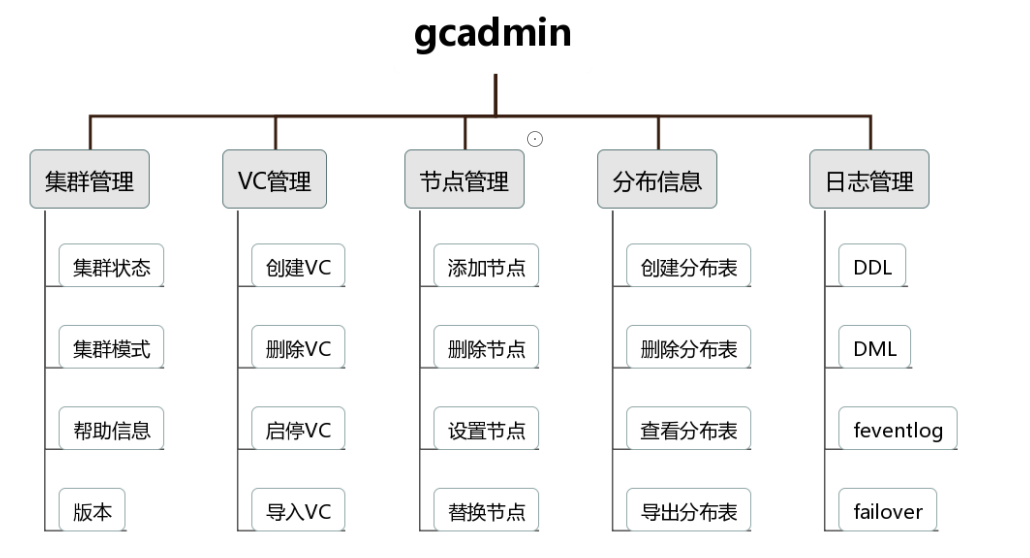
- 1 集群管理工具
- —1.1 简介
- —1.2 获取帮助
- —1.3 查看gcadmin版本
- 2 集群状态管理
- —2.1 查看集群状态
- —2.2 集群工作状态
- —2.3 集群模式
- —2.3 切换集群模式
- —2.4 模组进程状态
- —2.5 模组进程
- —2.6 模组监控工具
- —2.7 模组启停工具
- —2.8 数据一致性状态
- 3 集群错误日志信息
- —3.1 DDL event日志
- —3.2 DML event日志
- —3.3 DMLstorageevent 日志
- 4 故障倒换
- —4.1 Failover 日志
- —4.2 显示详细信息
- 5 分布信息管理
- —5.1 简介
- —5.2 distribution表
- —5.3 分片的分布规则
- —5.4 生成distribution表
- ——5.4.1 多rack
- ——5.4.2 负载均衡:(默认)
- ——5.4.3 节点高可用
- ——5.4.4 手动创建分片规则
- —5.5 导出distribution
- —5.6 查看distribution
- —5.7 删除distribution
1 集群管理工具
—1.1 简介
是专门为DBA管理员提供的用于对集群进行管理和监控的工具软件。 随GBase 8a数据库一起安装,部署在gcware/bin目录中。
—1.2 获取帮助
语法:$ gcadmin --help
—1.3 查看gcadmin版本
语法:$ gcadmin -V
2 集群状态管理
—2.1 查看集群状态
语法:gcadmin showcluster [c] [d] [f]
参数:
c:显示节点时仅显示 coordinator 节点;
d:显示节点时仅显示相应的数据节点;
f:指明按 xml 格式显示信息;
[gbase@gbase02 ~]$ gcadmin CLUSTER STATE: ACTIVE VIRTUAL CLUSTER MODE: NORMAL ============================================================ | GBASE COORDINATOR CLUSTER INFORMATION | ============================================================ | NodeName | IpAddress | gcware | gcluster | DataState | ------------------------------------------------------------ | coordinator1 | 10.0.0.11 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator2 | 10.0.0.12 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator3 | 10.0.0.13 | OPEN | OPEN | 0 | ------------------------------------------------------------ ========================================================================================================= | GBASE DATA CLUSTER INFORMATION | ========================================================================================================= | NodeName | IpAddress | DistributionId | gnode | syncserver | DataState | --------------------------------------------------------------------------------------------------------- | node1 | 10.0.0.11 | 1 | OPEN | OPEN | 0 | --------------------------------------------------------------------------------------------------------- | node2 | 10.0.0.12 | 1 | OPEN | OPEN | 0 | --------------------------------------------------------------------------------------------------------- | node3 | 10.0.0.13 | 1 | OPEN | OPEN | 0 | ---------------------------------------------------------------------------------------------------------
[gbase@gbase02 ~]$ gcadmin showcluster f
<?xml version='1.0' encoding="utf-8"?>
<ClusterInfo>
<CoordinatorClusterState>ACTIVE</CoordinatorClusterState>
<VirtualClusterMode>NORMAL</VirtualClusterMode>
<CoordinatorNodes>
<CoordinatorNode>
<NodeName>coordinator1</NodeName>
<IpAddress>10.0.0.11</IpAddress>
<gcware>OPEN</gcware>
<gcluster>OPEN</gcluster>
<DataState>0</DataState>
</CoordinatorNode>
<CoordinatorNode>
<NodeName>coordinator2</NodeName>
<IpAddress>10.0.0.12</IpAddress>
<gcware>OPEN</gcware>
<gcluster>OPEN</gcluster>
<DataState>0</DataState>
</CoordinatorNode>
<CoordinatorNode>
<NodeName>coordinator3</NodeName>
<IpAddress>10.0.0.13</IpAddress>
<gcware>OPEN</gcware>
<gcluster>OPEN</gcluster>
<DataState>0</DataState>
</CoordinatorNode>
</CoordinatorNodes>
<DataserverNodes>
<DataServerNode>
<NodeName>node1</NodeName>
<IpAddress>10.0.0.11</IpAddress>
<DistributionId>1</DistributionId>
<gnode>OPEN</gnode>
<syncserver>OPEN</syncserver>
<DataState>0</DataState>
</DataServerNode>
<DataServerNode>
<NodeName>node2</NodeName>
<IpAddress>10.0.0.12</IpAddress>
<DistributionId>1</DistributionId>
<gnode>OPEN</gnode>
<syncserver>OPEN</syncserver>
<DataState>0</DataState>
</DataServerNode>
<DataServerNode>
<NodeName>node3</NodeName>
<IpAddress>10.0.0.13</IpAddress>
<DistributionId>1</DistributionId>
<gnode>OPEN</gnode>
<syncserver>OPEN</syncserver>
<DataState>0</DataState>
</DataServerNode>
</DataserverNodes>
</ClusterInfo>
[gbase@gbase02 ~]$ gcadmin showcluster CLUSTER STATE: ACTIVE VIRTUAL CLUSTER MODE: NORMAL ============================================================ | GBASE COORDINATOR CLUSTER INFORMATION | ============================================================ | NodeName | IpAddress | gcware | gcluster | DataState | ------------------------------------------------------------ | coordinator1 | 10.0.0.11 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator2 | 10.0.0.12 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator3 | 10.0.0.13 | OPEN | OPEN | 0 | ------------------------------------------------------------ ========================================================================================================= | GBASE DATA CLUSTER INFORMATION | ========================================================================================================= | NodeName | IpAddress | DistributionId | gnode | syncserver | DataState | --------------------------------------------------------------------------------------------------------- | node1 | 10.0.0.11 | 1 | OPEN | OPEN | 0 | --------------------------------------------------------------------------------------------------------- | node2 | 10.0.0.12 | 1 | OPEN | OPEN | 0 | --------------------------------------------------------------------------------------------------------- | node3 | 10.0.0.13 | 1 | OPEN | OPEN | 0 | ---------------------------------------------------------------------------------------------------------
集群工作状态 :ACTIVE
集群模式:normal/readonly/recovery
模组进程状态:open / close / offline
数据一致性状态:0 / 1
—2.2 集群工作状态
[gbase@gbase02 ~]$ gcadmin CLUSTER STATE: ACTIVE VIRTUAL CLUSTER MODE: NORMAL ============================================================ | GBASE COORDINATOR CLUSTER INFORMATION | ============================================================ | NodeName | IpAddress | gcware | gcluster | DataState | ------------------------------------------------------------ | coordinator1 | 10.0.0.11 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator2 | 10.0.0.12 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator3 | 10.0.0.13 | OPEN | OPEN | 0 |
Active:表示集群工作正常。
提示:
当集群中coordinator 节点的Online个数小于或等于coordinator节点总数的1/2 时, 集群为了保障数据安全,相关的gcware服务会停用。此时不能执行任何数据库操作。
—2.3 集群模式
[gbase@gbase02 ~]$ gcadmin CLUSTER STATE: ACTIVE VIRTUAL CLUSTER MODE: NORMAL ============================================================ | GBASE COORDINATOR CLUSTER INFORMATION | ============================================================ | NodeName | IpAddress | gcware | gcluster | DataState | ------------------------------------------------------------ | coordinator1 | 10.0.0.11 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator2 | 10.0.0.12 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator3 | 10.0.0.13 | OPEN | OPEN | 0 |
● Normal模式: 集群正常模式,能执行所有SQL操作。
● Readonly模式: 只读模式,只能执行SQL查询操作,不能执行DDL/DML/Loader操作。在执行扩容、替换或数据备份操作时集群会在一段时间内处于只读模式。
● Recovery模式: 备份恢复模式,一般在执行集群数据恢复或特定场景时,使用该模式。该模式下,不允许进行任何SQL操作。
注:管理员可以手动切换模式。
—2.3 切换集群模式
语法:gcadmin switchmode <mode>
[gbase@gbase02 ~]$ gcadmin switchmode readonly ========== switch cluster mode... switch pre mode: [NORMAL] switch mode to [READONLY] switch after mode: [READONLY] [gbase@gbase02 ~]$ gcadmin CLUSTER STATE: ACTIVE VIRTUAL CLUSTER MODE: READONLY ============================================================ | GBASE COORDINATOR CLUSTER INFORMATION | ============================================================ | NodeName | IpAddress | gcware | gcluster | DataState | ------------------------------------------------------------ | coordinator1 | 10.0.0.11 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator2 | 10.0.0.12 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator3 | 10.0.0.13 | OPEN | OPEN | 0 | ------------------------------------------------------------
—2.4 模组进程状态
• Open状态:模组工作状态正常。
• Offline状态:模组进程下线,一般为硬件故障,可排查设备是否突然断电或断网等。修复故障后,需重启相关进程。
• Close状态:模组进程启动失败或意外关闭等。 常见原因如:端口被占用,配置文件 权限和参数错误等。须查看相关日志 查找原因并重启相关进程。
[gbase@gbase02 ~]$ gcadmin CLUSTER STATE: ACTIVE VIRTUAL CLUSTER MODE: NORMAL ============================================================ | GBASE COORDINATOR CLUSTER INFORMATION | ============================================================ | NodeName | IpAddress | gcware | gcluster | DataState | ------------------------------------------------------------ | coordinator1 | 10.0.0.11 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator2 | 10.0.0.12 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator3 | 10.0.0.13 | OPEN | OPEN | 0 | ------------------------------------------------------------ ========================================================================================================= | GBASE DATA CLUSTER INFORMATION | ========================================================================================================= | NodeName | IpAddress | DistributionId | gnode | syncserver | DataState | --------------------------------------------------------------------------------------------------------- | node1 | 10.0.0.11 | 1 | OPEN | OPEN | 0 | --------------------------------------------------------------------------------------------------------- | node2 | 10.0.0.12 | 1 | OPEN | OPEN | 0 | --------------------------------------------------------------------------------------------------------- | node3 | 10.0.0.13 | 1 | OPEN | OPEN | 0 | ---------------------------------------------------------------------------------------------------------
—2.5 模组进程
• Coordinator node: gcluster进程名:gclusterd
gcware进程名: gcware
自动恢复进程名:gcrecover
• Data node:
gnode进程名:gbased
syncserver进程名:gc_sync_server
监控工具名:gcmonit / gcmmonit
—2.6 模组监控工具
语法: gcmonit <--start|--stop|--restart|--status[=<prog_name>]|--help|--version>
[gbase@gbase02 ~]$ gcmonit --status +--------------------------------------------------------------------------------+ |SEG_NAME PROG_NAME STATUS PID | +--------------------------------------------------------------------------------+ |gcluster gclusterd Running 7013 | |gcware gcware Running 7008 | |gcrecover gcrecover Running 7032 | |gcmmonit gcmmonit Running 7601 | |gbase gbased Running 7055 | |syncserver gc_sync_server Running 7078 | +--------------------------------------------------------------------------------+
注:gcmmonit 与 gcmonit 实现的功能完全一致,只是它们的监测范围不同。
• gcmonit负责监测 GBase 8a MPP Cluster 各个服务程序和 gcmmonit 程序的运行状况;
• gcmmonit 只负责监测 gcmonit 程序的运行状况。
语法:gcmmonit <--start|--stop|--restart|--help|--version>
—2.7 模组启停工具
语法:gcluster_services <gbase|gcluster|gcrecover|syncserver|all> <start|stop[--force] | restart [--force]|info>
参数说明:
• force:用于服务无法停止时,内部用 kill -9 即 kill -KILL 的方式强制停止服务进程。
• info:显示进程当前运行状态。
[gbase@gbase02 ~]$ gcluster_services all info gcware is running gcluster is running gcrecover is running gbase is running syncserver is running [gbase@gbase02 ~]$ gcluster_services all stop Stopping GCMonit success! Stopping gcrecover : [ OK ] Stopping gcluster : [ OK ] Stopping gcware : [ OK ] Stopping gbase : [ OK ] Stopping syncserver : [ OK ] [gbase@gbase02 ~]$ gcluster_services all start Starting gcware : [ OK ] Starting gcluster : [ OK ] Starting gcrecover : [ OK ] Starting gbase : [ OK ] Starting syncserver : [ OK ] Starting GCMonit success!
[gbase@gbase02 ~]$ gcmonit --start
注:GCMonit开启后,异常关闭的进程会自动拉起。
—2.8 数据一致性状态
• 0 : 主备分片数据一致
• 1:主备分片数据不一致
系统自动恢复:
gcrecover 先恢复 DDL 操作,然后调用同步服务 gc_sync_server 恢复数据。恢复后,系统自动将 1 转换为 0。
自动恢复原理:
当某个节点执行命令失败后,数据恢复工具可监控到错误日志,然后调用同步工具,自动修复节点数据不一致的情况, 确保各节点数据的一致性。
[gbase@gbase02 ~]$ gcadmin CLUSTER STATE: ACTIVE VIRTUAL CLUSTER MODE: NORMAL ============================================================ | GBASE COORDINATOR CLUSTER INFORMATION | ============================================================ | NodeName | IpAddress | gcware | gcluster | DataState | ------------------------------------------------------------ | coordinator1 | 10.0.0.11 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator2 | 10.0.0.12 | OPEN | OPEN | 0 | ------------------------------------------------------------ | coordinator3 | 10.0.0.13 | OPEN | OPEN | 0 | ------------------------------------------------------------ ========================================================================================================= | GBASE DATA CLUSTER INFORMATION | ========================================================================================================= | NodeName | IpAddress | DistributionId | gnode | syncserver | DataState | --------------------------------------------------------------------------------------------------------- | node1 | 10.0.0.11 | 1 | OPEN | OPEN | 0 | --------------------------------------------------------------------------------------------------------- | node2 | 10.0.0.12 | 1 | OPEN | OPEN | 0 | --------------------------------------------------------------------------------------------------------- | node3 | 10.0.0.13 | 1 | OPEN | OPEN | 0 | ---------------------------------------------------------------------------------------------------------
3 集群错误日志信息
—3.1 DDL event日志
在DDL语句执行成功的情况下,记录执行过程中出现异常造成主备分片不一致的节点信息。
语法: gcadmin showddlevent [<表名 段名 节点IP>|<最大返回数>]
参数说明:
表名: 格式为库名.表名
段名: 表分片的名字,例如建立一张分布表,在第一个节点上的表分片名就是n1,在第二个节点上的 表分片名就是n2,……,依此类推。
节点IP: 节点机器的IP
最大返回数:默认返回16 条,超过部分将不显示。
$ gcadmin showddlevent Vc event count:2 Event ID: 2 ObjectName: nosame Fail Node Copy: ------------------------------------------------------ Fail Data Copy: ------------------------------------------------------ NodeIP: 10.0.0.13 FAILURE Event ID: 3 ObjectName: nosame.abc Fail Node Copy: ------------------------------------------------------ Fail Data Copy: ------------------------------------------------------ SegName: n3 NodeIP: 10.0.0.13 FAILURE SegName: n6 NodeIP: 10.0.0.13 FAILURE
—3.2 DML event日志
在DML语句执行成功的情况下,记录造成主备分片不一致的异常节点的信息。
语法: gcadmin showdmlevent [<表名 段名 节点IP>|<最大返回数>]
参数说明:
表名: 格式为库名.表名
段名: 表分片的名字,例如建立一张分布表,在第一个节点上的表分片 名就是n1,在第二个节点上的表分 片名就是n2,……,依此类推。
节点IP: 节点机器的IP
最大返回数:默认返回16 条,超过部分将不显示。
$ gcadmin showdmlevent Vc event count:1 Event ID: 2 ObjectName: nosame.abc Fail Data Copy: ------------------------------------------------------ SegName: n1 SCN: 131075 NodeIP: 10.0.0.13 FAILURE
—3.3 DMLstorageevent 日志
执行DML成功的情况下,记录识别出的数据或元数据文件损坏的异常节点信息。
语法: gcadmin showdmlstorageevent [<表名 段名 节点IP>|<最大返回数>]
参数说明:
表名: 格式为库名.表名
段名: 表分片的名字,例如建立一张分布表,在第一个节点上的表分片名就是n1,在第二个节点上的表分片名就是 n2,……,依此类推。
节点IP: 节点机器的IP
最大返回数:默认返回16 条,超过部分将不显示。
$ gcadmin showdmlstorageevent Event count:1 Event ID: 5 ObjectName: test.t1 TableID: 26 Fail Data Copy: ------------------------------------------------------ SegName: n2 NodeIP: 10.0.0.12 FAILURE
4 故障倒换
—4.1 Failover 日志
当执行某SQL的管理节点出现故障,无法正常完成SQL操作时,接管节点将读取记 录于gcware中的SQL执行信息继续执行。该过程就是管理节点的failover机制。
语法:
gcadmin showfailover
Failover 信息记录的内容:
Commit id ,Database 名,Table名,Scn 号,Type, Create time,
State,original node,takeover node,Takeover 接管次数。
示例:
$ gcadmin showfailover +=========================================================================================+ | GCLUSTER FAILOVER | +=========================================================================================+ + | commit id | database | table | scn | type | create time | state | original node | takeover node | takeover number| +------------+------------+-----------+---------+-----------+------------------+-------+-----------------+--- --------------+------------------+ | 1 | test | t1 | 1 | ddl | 20161019101114| 5 | 192.168.153.130| 0.0.0.0 | 0 | +------------+------------+-----------+------------+-----------+------------------+-------+-----------------+--- --------------+------------------+
显示说明:
commit id: failover 的唯一标识,64 位数字。
database: 数据库名。
table: 表名。
scn: scn 号。
type: ddl/dml/rebalance。
create time: 当前节点创建 failover 的时间。
original node: 发起节点。
takeover node: 当前接管节点,如果没有发生接管则显示为 0.0.0.0。
takeover num: failover 的接管次数,gcware 通知 gcluster 接管后这个值就加 1。
state: failover 对应的状态当前如下:
• init:初始化,对应显示数字 0
• add_res : 添加集群锁,对应显示数字 1
• set_info : 设置 failover 信息,对应显示数字 2
• set_status: 设置分片状态,对应显示数字 3
• set_rebalance_info:设置 rebalance 信息,对应显示数字 4
• set_rebalance_status:设置 rebalance 状态,对应显示数字 5
—4.2 显示详细信息
语法:
gcadmin showfailoverdetail <commitid> [ xml_file_name ]
参数:
Commitid:failover 的唯一标识,该参数必须输入。同gcadmin showfailover的Commitid; Xml_fil_name:保存 failover 信息的文件名,可选,若不输入则将failover 信息打印到屏幕;
增加的内容:
content:failover 完整信息,最大 256k。
status:failover 操作的对象状态即对应的是哪个节点哪个分片的状态。例如 node1.n1 init 含义就是 node1 节点上 n1 分片尚未提交处于初始化状态。
rebalance_information:rebalance 独有信息( 含distribution_id, current_scn, current_step, 中间表名),ddl dml 显示为空标签。
sdm: 仅用于rebanlance,由如下字段联接而成:
NodeId.Suffix : 某个节点的某个分片;
curRowid:rebalance 执行到哪一行了;
Blockid BlockNum:上一批 rebalance 执行到哪一行;
示例:
$ gcadmin showfailoverdetail 1 <?xml version='1.0' encoding="utf-8"?> <failover_detail> <failover_information> <commit_id>1</commit_id> <database>test</database> <table>t1</table> <scn>1</scn> <type>ddl</type> <create_time>20161019101114</create_time> <state>5</state> <original_node>192.168.153.130</original_node > <takeover_node>0.0.0.0</takeover_node> <takeover_number>0</takeover_number> </failover_information> <content>create table t1(a int)</content> <status> </status> <rebalance_information> <distribution_id>1</distribution_id> <current_scn>10</current_scn> <current_step>3</current_step> <table>tmpt1</table> </rebalance_information> <sdm> <slice_dm>from_slice node1.n1.row10.block_id1</slice_dm> <slice_dm>from_slice node2.n2.row9.block_id2</slice_dm> <slice_dm>from_slice node3.n3.row8.block_id3</slice_dm> </sdm> </failover_detail>
5 分布信息管理
—5.1 简介
即对distribution表的管理。gcadmin工具提供对distribution表的创建、删除和导出等操作。
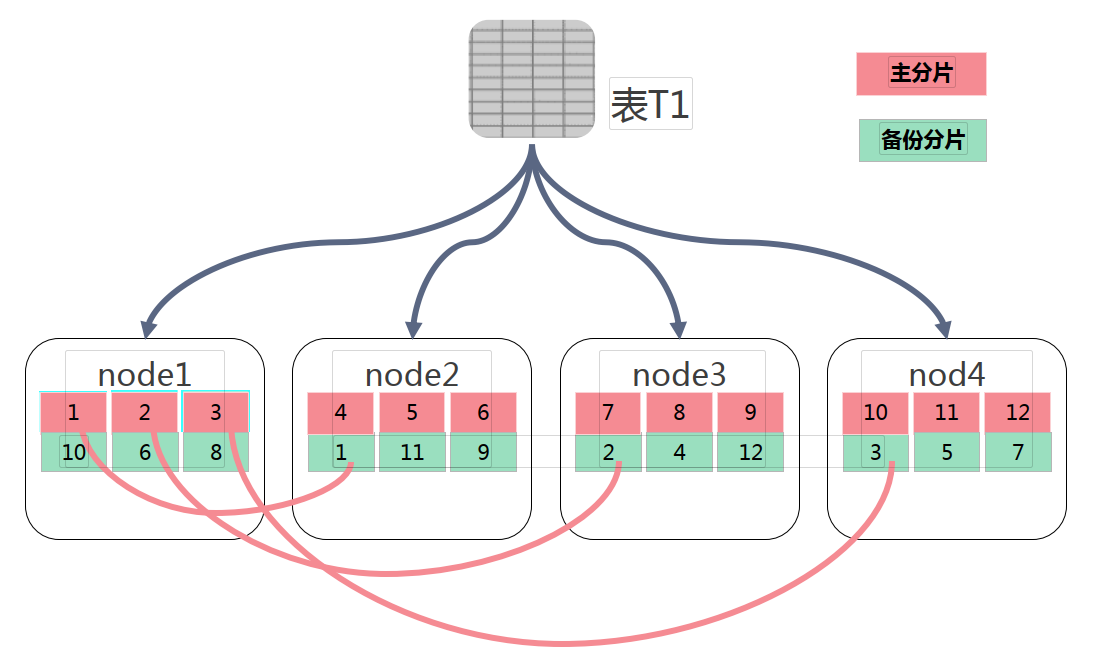
—5.2 distribution表
是用于记录分片和节点对映关系的表。
注:通过指定不同的分片备份规则,distribution表可协助集 群实现节点数据的高可用及数 据访问的负载均衡。
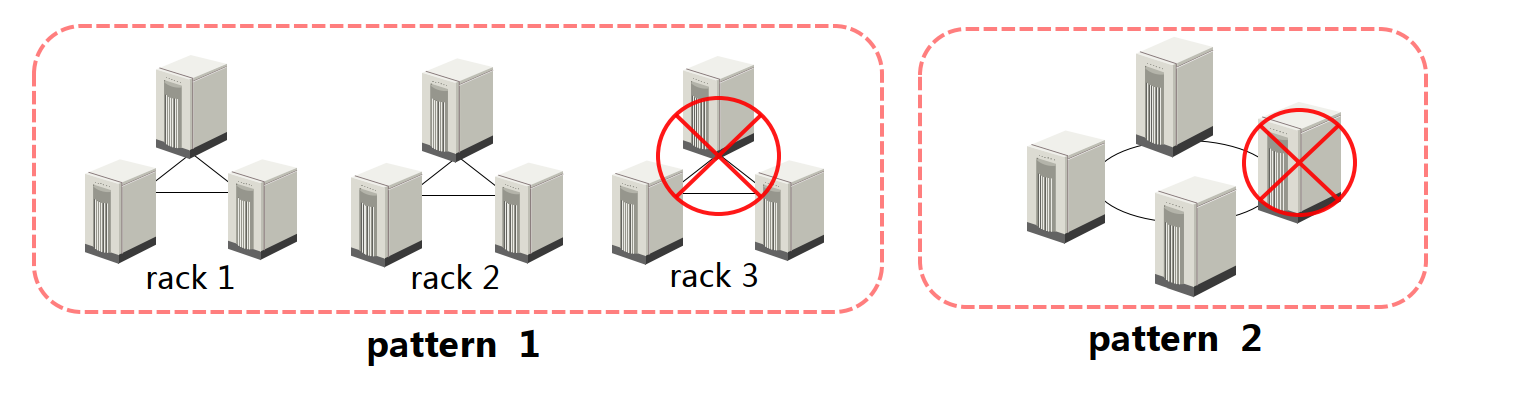
—5.3 分片的分布规则
1、按照模板生成分片并备份:
• pattern 1 (rack高可用+负载均衡)
• pattern 2 (节点高可用)
2、手动指定:
• 自定义模式(需编写xml分片配置文件,自定义高可用方案)
—5.4 生成distribution表
语法:
gcadmin distribution <gcChangeInfo.xml> <p number> [d number] [pattern 1|2] 参数说明:
gcChangeInfo.xml: 是描述集群内节点和rack(机柜)对应关系的文件。
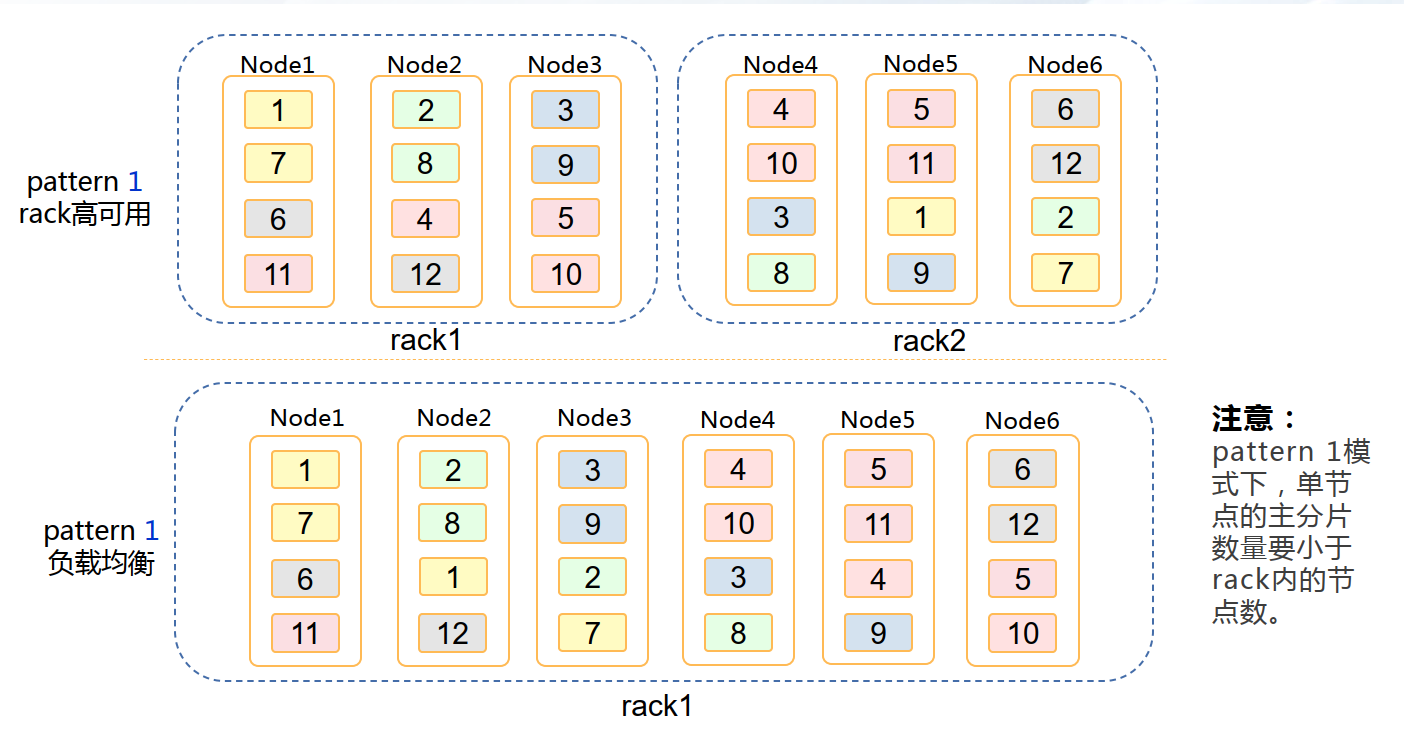
p:每个数据节点存放的主分片数量。注:pattern 1模式下,p的取值范围为:1<=p<rack内节点数。
d:每个主分片的备份数量,取值为0,1 或2。默认值为1。
pattern:描述分片备份规则的模板。1 为rack高可用,2 为节点高可用。默认为 1。
——5.4.1 多rack
注:集群安装时所有数据节点默认 在同一rack内。划分多rack时,需 修改gcChangeInfo.xml文件。
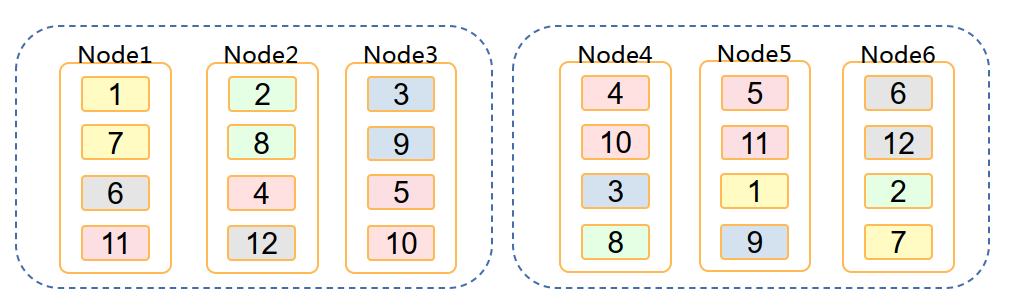
语句:
$gcadmin distribution gcChangeInfo.xml p 2 d 1 pattern 1 <?xml version="1.0" encoding="utf-8"?> <servers> <rack> <node ip="10.0.0.11"/> <node ip="10.0.0.12"/> <node ip="10.0.0.13"/> </rack> <rack> <node ip="10.0.0.14"/> <node ip="10.0.0.15"/> <node ip="10.0.0.16"/> </rack> </servers>
——5.4.2 负载均衡:(默认)
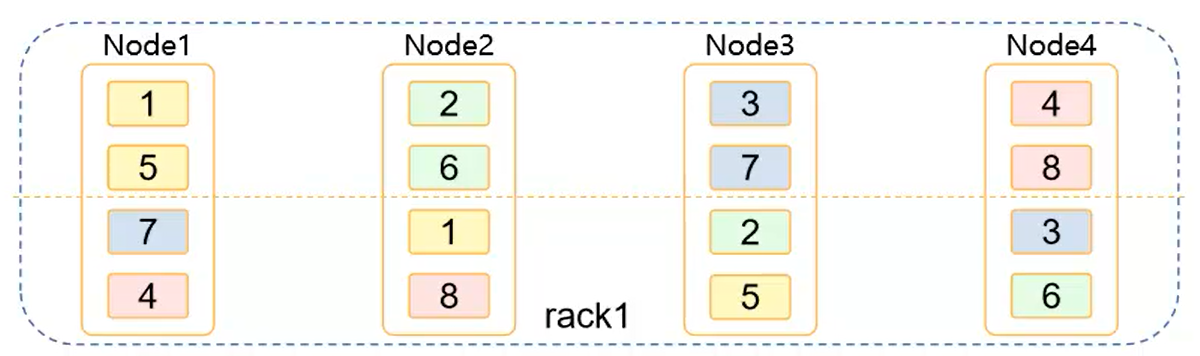
语句:
$gcadmin distribution gcChangeInfo.xml p 2 d 1 pattern 1 <?xml version="1.0" encoding="utf-8"?> <servers> <rack> <node ip="172.16.4.131"/> <node ip="172.16.4.132"/> <node ip="172.16.4.133"/> <node ip="172.16.4.134"/> </rack> </servers>
注:集群安装时所有数据节点默认 在同一rack内,无需修改 gcChangeInfo.xml文件。
——5.4.3 节点高可用
注:因pattern2模式没有rack概念, 所以gcChangeInfo.xml文件中的 rack不起作用,无需修改。
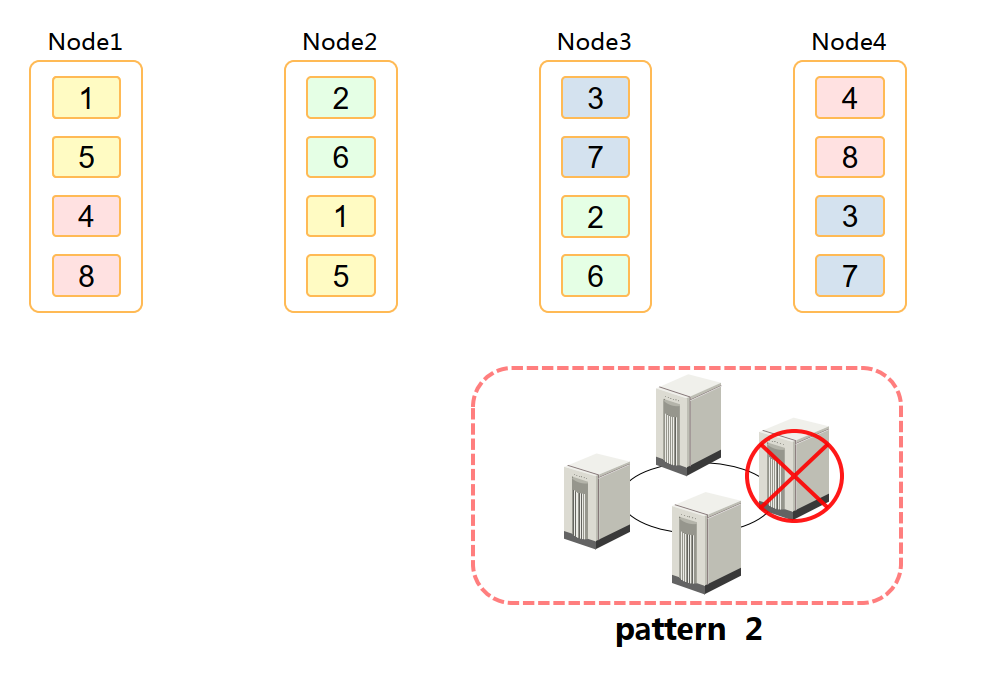
语句:
$gcadmin distribution gcChangeInfo.xml p 2 d 1 pattern 2 <?xml version="1.0" encoding="utf-8"?> <servers> <rack> <node ip="172.16.4.131"/> <node ip="172.16.4.132"/> <node ip="172.16.4.133"/> <node ip="172.16.4.134"/> </rack> </servers>
——5.4.4 手动创建分片规则
语句:
$gcadmin distribution gcChangeInfo.xml 修改节点信息文件gcChangeInfo.xml: <?xml version="1.0" encoding="utf-8"?> <servers> <cfgFile file="example.xml"/> </servers>
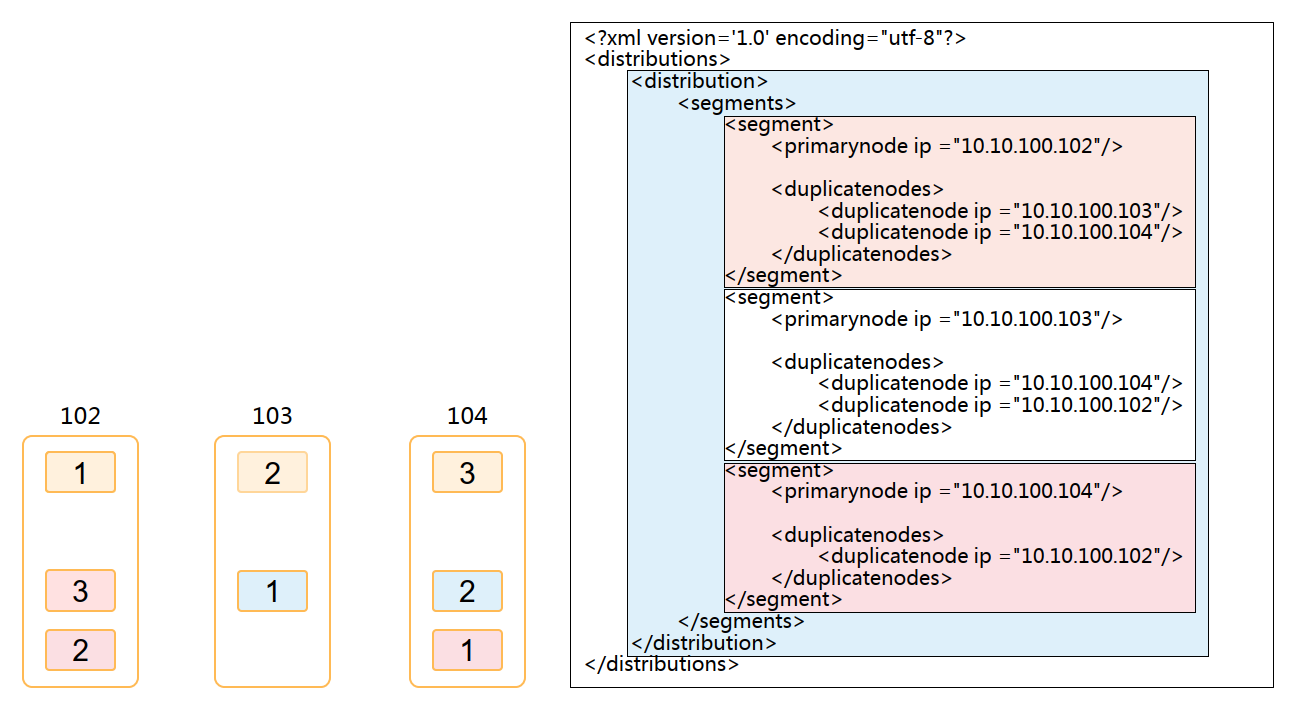
—5.5 导出distribution
功能:
将指定 ID 的 distribution 信息保存在指定的文件中,生成的文件为 xml 文件,用户可修改文件中的 分片信息,然后使用该文件重新生成distribution。
语法:
gcadmin getdistribution <ID> <distribution_info.xml>
参数说明:
ID:要获取的 distribution id。
distribution_info.xml:保存 distribution 信息的文件名。
示例:
gcadmin getdistribution 1 distribution_info.xml
打开distribution_info.xml文件,显示如下内容:
<?xml version='1.0' encoding="utf-8"?> <distributions> <distribution> <segments> <segments> <primarynode ip=”10.0.0.107”/> <duplicatenodes> <duplicatenode ip=”10.0.0.108”/> </duplicatenodes> </segments> <segments> <primarynode ip=”10.0.0.108”/> <duplicatenodes> <duplicatenode ip=”10.0.0.109”/> </duplicatenodes> </segments> ... ... </segments> </distribution> </distributions>
—5.6 查看distribution
语法:
gcadmin showdistribution [node | f]
参数说明:
node:按节点为单位,显示各节点分片 f:以xml文件格式显示
[gbase@localhost ~]$ gcadmin showdistribution node Distribution ID: 5 | State: new | Total segment num: 4 =========================================== | nodes | 172.16.4.140 | 172.16.4.141 | ------------------------------------------------------------------------ | primary | 1 | 2 | | segments | 3 | 4 | ------------------------------------------------------------------------ | duplicate | 2 | 1 | | segments 1 | 4 | 3 | ===========================================
[gbase@localhost ~]$ gcadmin showdistribution Distribution ID: 5 | State: new | Total segment num: 4 Primary Segment Node IP Segment ID Duplicate Segment node IP =============================================== | 172.16.4.140 | 1 | 172.16.4.141 | -------------------------------------------------------------------------------- | 172.16.4.141 | 2 | 172.16.4.140 | -------------------------------------------------------------------------------- | 172.16.4.140 | 3 | 172.16.4.141 | -------------------------------------------------------------------------------- | 172.16.4.141 | 4 | 172.16.4.140 | ===============================================
—5.7 删除distribution
从集群中删除指定 id 的 distribution。若不输入 distribution id,则默认删除旧的 distribution,集 群中只有一个 distribution 时则默认删除该 distribution。
语法:
gcadmin rmdistribution [ID]
• 若distribution 为正在使用,则无法删除该 distribution。需先在数据库中执行
refreshnodedatamap drop <ID>操作才可删除;
• 若 distribution 中有 fevent log 需先清除才可删除该 distribution;
• 删除 distribution 时,需要先确认所有的 GCluster 节点服务正常,若有 GCluster 节点服务不正常,会导致删除 distribution 后产生无法恢复的 fevent log。