
读写分离集群是基于即时归档或实时归档实现的高性能数据库集群,不但提供数据保护、容灾等数据守护基本功能,还具有读写操作自动分离、负载均衡等特性。读写分离集群对多可以配置8个即时备库或8个实时备库,提供数据同步、备库故障自动处理、故障恢复自动数据同步等功能,也支持自动故障切换和手动故障切换两种守护模式。
一般情况下,应用系统中查询等只读操作的比例远大于 Insert/Delete/Update 等 DML 操作,修改对象定义等 DDL 操作的比例则更低。但是,这些操作往往混杂在一起,在 高并发、高压力情况下,会导致数据库性能下降,响应时间变长。借助读写分离集群,将只 读操作自动分发到备库执行,可以充分利用备库的硬件资源,降低主库的并发访问压力,进 而提升数据库的吞吐量。
读写分离集群不依赖额外的中间件,而是通过数据库接口与数据库之间的密切配合,实 现读、写操作自动分离特性。DM 的 JDBC、DPI、DCI、ODBC、Provider 等接口都可以 用来部署读写分离集群。
根据是否满足读提交事务隔离级特性,读写分离集群可以配置为事务一致模式和高性能 两种模式。简单的说,事务一致模式下,不论一个 Select 语句是在备库执行、还是在主 库执行,其查询结果集都是一样的。高性能模式则不能保证查询是一致的,备库的数据与主 库的数据同步存在一定的延迟,当 Select 语句发送到备库执行时,返回的有可能是主库 上一个时间点的数据。
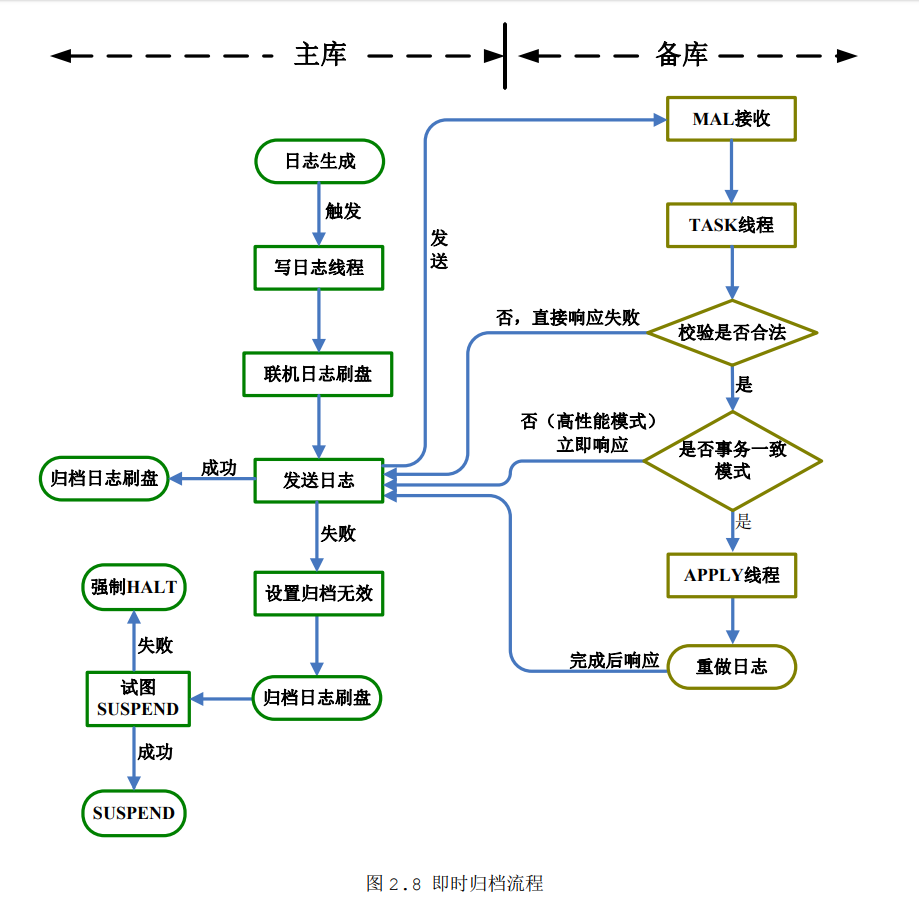
归档流程
读写分离集群可以配置为即时归档,也可以配置为实时归档,这两种配置方式仅仅是归档流程上有差别,读写分离集群的特性仍然是一致的。即时归档与实时归档流程存在一定差异:
1、主库先将日志写入本地联机redo日志文件中,在发送rlog_pkg到备库。
2、备库日志重演时机有两种选择:
事务一致模式:要求备库在重演redo日志完成后在响应主库。
高性能模式:与实时归档一样,收到redo日志后,马上响应主库。
3、即时归档的同步机制可以保证备库的redo日志不会比主库的redo日志多,因此即时备库不需要keep_pkg,收到rlog_pkg直接加入apply任务系统,启动redo日志重演。
4、备库故障或主备之间网络故障,导致发送rlog_pkg失败后,主句马上修改即时归档为invalid状态,并切换数据库为suspend状态。
5、即时归档修改为invalid状态后,会强制断开对应此备库上存在影子会话的用户会话,避免只读操作继续分发到该备库,导致查询数据不一致。
实现原理
实现读写分离集群的基本思路是:利用备库提供只读服务、无法修改数据的特性,优先将所有操作发送到备库执行,一旦备库执行报错,则发送到主库重新执行。通过备库试错这么一个步骤,自然的将只读操作分流到备库执行,并且,备库试错由接口层自动完成,对应用透明。
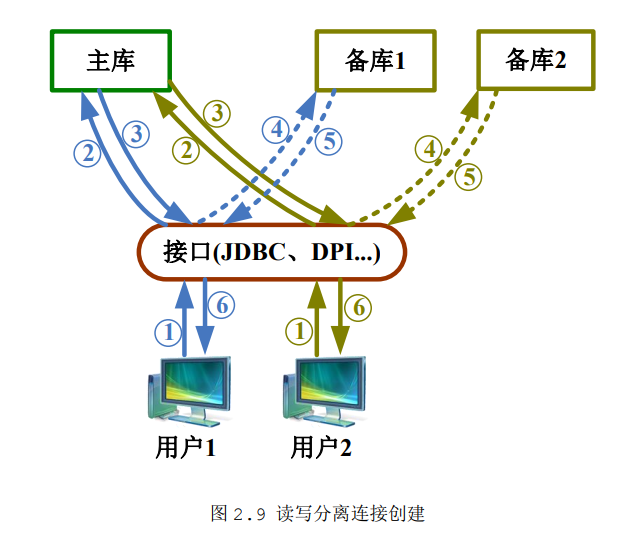
读写分离集群数据连接创建流程:
1、用户发起数据库连接请求。
2、接口(JDBC\DPI等)根据服务名配置(在dm_svc.conf中进行配置)登录主库。
3、主库挑选一个有效即时备库的IP/Port返回给接口。
4、接口根据返回的备库IP和port信息,向备库发起一个连接请求。
5、备库返回连接成功信息。
6、接口响应用户数据库连接创建成功。
接口在备库上创建的连接时读写分离集群自动创建的;对用户而言,就是在主库上创建了一个数据库连接。
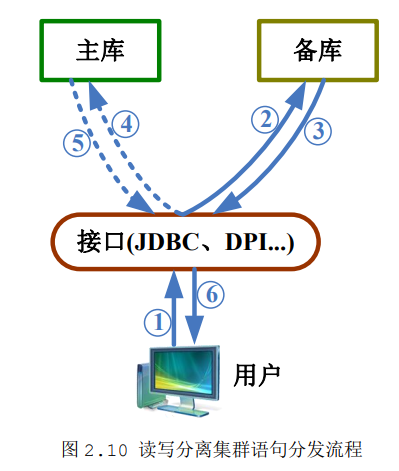
1、接口收到用户的请求。
2、接口优先将sql发送到备库。
3、执行。
5、主库执行并返回执行结果给接口。一旦主库上执行的写事物提交,则下次继续从第一部开始。备库执行并返回执行结果,如果接口收到的是备库执行成功消息,则转到第六步,如果接口收到的是备库执行失败消息,则转到第4步。
4、重新将执行失败的sql发送到主库执行,只要第三步中的sql在备库执行失败,则同一事物后续所有操作(包括只读操作)都会直接发送到主库
6、接口响应用户并将执行结果返回给用户
事物一致性
读写分离集群通过JDBC\DPI等接口自动分发语句,一个事务包含的多个语句可能分别在备库和主库上执行,但执行结果与单独在一个数据库实例上完全一致,满足读提交事务隔离级特性。
读写分离集群通过JDBC\DPI等接口自动分发语句,一个事务包含的多个语句可能分别在备库和主库上执行,但执行结果与单独在一个数据库实例上完全一致,满足读提交事务隔离级特性。

根据读写分离特性,trx1 的 UPDATE 在主库执行;trx2 的 SELECT 语句在备库执行, INSERT 语句转到主库执行,并且 trx2 的 INSERT 语句的插入值,是从之前执行的 SELECT 结果集中获取。
下面根据即时归档流程,结合 trx2 执行 SELECT 语句时机和以及 trx1 的不同状态进 行讨论,详细地说明读写分离集群是如何实现提交事务隔离级别的。
1、第一种,TRX2执行select时,trx1的commit还未执行。
trx2 的 SELECT 语句,无论是在主库还是备库执行,查询结果都是 trx1 更新 T 表之 前的值,var_x = 1。
2. 第二种情况,trx2 执行 SELECT 时,trx1 的 COMMIT 已经执行完成。 trx2 的 SELECT 语句,无论是在主库还是备库执行,查询结果都是 trx1 更新 T 表后 的值,var_x = 2。
3. 第三种情况,trx2 执行 SELECT 时,trx1 正在执行 COMMIT。 trx2 的 SELECT 查询结果,与两个语句在系统内部的执行顺序有关,var_x 的值可能 是 1 或者 2。但由于 trx1 的 COMMIT 并没有明确响应用户,var_x 的最终值取决于数据 库管理系统的实现策略,无论返回 1 还是 2,都符合读提交事务隔离级。
为了保证主备库上的一致性,目前读写分离集群有下列一些类型的语句不会在备库上执 行,都在主库上执行:
1、设置会话、事务为串行化隔离级语句。
2、表对象上锁语句(lock table xx in exclusive mode)。
3、查询上锁语句(select for update)。
4、备份相关系统函数。
5、自治事务操作。
6、包操作。
7、动态视图查询。
8、设置自增列操作语句(set identity)insert table on。)
9、临时表查询
10、访问@@IDENTITY、@@ERROR等全局变量。
11、SF_GET_PARA_STRING_VALUE、SF_GET_PARA_DOUBLE_CALUE等函数。
读写分离集群中,当一个 SQL 从备库切换到主库执行时,主库会启动一个新 的事务,主库事务与备库事务没有任何联系,事务 ID 也完全不同。备库事务 ID 与主库事务 ID 分配机制并不相同,主库的事务 ID 取值范围是[1 ~ 0x7FFFFFFFFFFF], 备库 事务 ID 取 值范围是 [0x800000000000 ~ 0xFFFFFFFFFFFF]; 备库 事务 ID 是一个 内存 值,每 次重启 后都从 0x800000000000 开始重新分配;主库事务 ID 是一个物理值,一旦分配后, 就不会再重复分配。
性能调整
根据读写分离语句分发流程可以发现,当一个应用系统中只读事务占绝大多数情况下, 可能出现备库高负载、高压力,主库反而比较空闲的情况。为了实现负载均衡,更好地利用 主备库的硬件资源,JDBC 等数据库接口提供了配置项,允许将一定比例的只读事务分发到 主库执行。因此,用户应该根据主备库的负载情况,灵活调整接口的分发比例 rwPercent 配置项,以获得最佳的数据库性能。
备库数量是影响读写分离集群性能的一个重要因素,备库越多则每个备库需要承担的任 务越少,有助于提升系统整体并发效率。另外,事务一致模式下,主库要等所有备库重演 Redo 日志完成后,才能响应用户,随着备库的增加,即时归档时间会变长,最终降低非只 读事务的响应速度。因此,部署多少备库,也需要综合考虑硬件资源、系统性能等各种因素。
配置为高性能模式,则是提升读写分离集群的另一个有效手段。如果应用系统对查询结 果实时性要求并不太高,并且事务中修改数据的操作也不依赖同一个事务中的查询结果。那 么,通过修改 dmarch.ini 中的 ARCH_WAIT_APPLY 配置项为 0,将读写分离集群配置为 高性能模式,可以大幅提高系统整体性能。如果应用包含以下代码逻辑,则不适合使用高性 能模式:
实时归档的读写分离
实时主备也可以配置接口的读写分离属性进行访问,实现读写分离功能特性。
实时读写分离同样也支持事务一致模式和高性能模式,由配置文件 dmarch.ini 中的 ARCH_WAIT_APPLY 配置项来确定,1 表示事务一致模式,0 表示高性能模式,实时读写分 离下,默认值为 0,即采用高性能模式。这个参数在实时归档中的用法和在即时归档中是相 同的,只是默认值不同。
和即时归档不同的是,实时归档先发送日志到备库,然后再写入本地联机日志,和即时 归档相比,实时归档的读写分离可以有效避免备库自动接管后老主库的分裂,在对读写分离 集群的可用性要求比较高的情况下,可以采用这种配置方式。
!!!!!注意:实时读写分离的事务一致模式仅在数据守护配置为自动切换模式下才会生效。
内容来自官方文档!