文章目录
- 1. 系统中的符号信息分类
- 2. 系统特殊符号
- —2.1 基础符号系列
- ——2.1.1 符号 $ 的两个作用
- ——2.1.2 符号 ! 的三个作用
- ——2.1.3 符号 | 的一个作用
- ——2.1.4 符号 # 的两个作用
- —2.2 引号符号系列
- —2.3 重定向符号
- —2.4 逻辑符号系列
- 3. 系统通配符号waildcard
- —3.1 符号 * 匹配所有信息
- —3.2 符号 {} 产生序列信息
- ——3.2.1 连续序列
- ——3.2.2 生成不连续序列
- ——3.2.3 生成组合序列
- ——3.2.4 快速备份文件命令
- ——3.2.5 快速还原数据方法
- 4. 系统正则符号
- —4.1 基础正则符号
- ——4.1.1 尖角符号:^
- ——4.1.2 美元符号 $
- ——4.1.3 尖角美元符号 ^$
- ——4.1.4 点符号 .
- ——4.1.5 星号符号 *
- ——4.1.6 点和星号组合 .*
- ——4.1.7 转译符号 \
- ——4.1.8 括号符号 []
- ——4.1.9 尖号和中括号组合使用 : [^]^[]
- —4.2 正则符号注意事项
- —4.3 扩展正则符号
- ——4.3.1 加号符号 +
- ——4.3.2 竖线符号:|
- ——4.3.3 小括号符号 ()
- ——4.3.4 大括号符号 {}
- ——4.3.5 问号符号 ?
1. 系统中的符号信息分类
系统特殊符号
系统通配符号
系统正则符号
作用:查询信息的时候,会带来便利
2. 系统特殊符号
—2.1 基础符号系列
——2.1.1 符号 $ 的两个作用
1)调取变量信息
[root@linux ~]# oldboy=123
[root@linux ~]# echo $oldboy
123
b 区分用户类型
如:$ 普通用户
c 结合awk对文件进行取列
[root@linux ~]# xargs -n 2 <test01.txt|awk '{print $2}'
02
04
06
08
10
[root@linux ~]# xargs -n 2 <test01.txt|awk '{print $1}'
01
03
05
07
09
[root@linux ~]# xargs -n 2 <test01.txt|awk '{print $0}'
01 02
03 04
05 06
07 08
09 10
——2.1.2 符号 ! 的三个作用
1)强制的作用 wq!
2)可以实现取反
[root@linux ~]# awk '!/oldgirl/' test02.txt
oldboy01
oldboy02
oldboy03
oldboy04
[root@linux ~]# ll /oldboy_dir/
total 8
drwxr-xr-x 2 root root 6 Feb 4 2019 oldboy01
-rw-r--r-- 1 root root 30 Jan 16 09:16 test01.txt
-rw-r--r-- 1 root root 46 Jan 16 09:39 test02.txt
-rw-r--r-- 1 root root 0 Jan 16 09:08 test03.txt
-rw-r--r-- 1 root root 0 Jan 16 09:08 test04.txt
-rw-r--r-- 1 root root 0 Jan 16 09:08 test05.txt
[root@linux ~]# find /oldboy_dir/ ! -type f
/oldboy_dir/
/oldboy_dir/oldboy01
3)!命令 可以快速调取执行历史命令(慎用)
[root@linux ~]# !find
find /oldboy -type f -mtime -1
cat ~/.bash_history -- 记录历史命令信息, 但是不会实时记录
history -- 显示所有输入过的历史命令
history -c --删除历史命令
history -W 将内存中记录的历史命令保存到~/.bash_history文件中
ctrl + r --搜索历史命令
作用:
01. 查看你的错误操作,确认错误原因
02. 回顾高手的操作过程
——2.1.3 符号 | 的一个作用
1)实现管道功能
将前一个命令执行的结果交给管道后面的命令进行处理
一般管道符号 会经常和xargs命令配合使用
批量删除操作
find /oldboy -type f -name "oldboy*.txt"|xargs rm
find /oldboy_dir/ -type f -delete
find /oldboy_dir/ -type f -exec rm -f {} \;
—2.1 基础符号系列
——2.1.1 符号 $ 的两个作用
1)调取变量信息
[root@linux ~]# oldboy=123
[root@linux ~]# echo $oldboy
123
b 区分用户类型
如:$ 普通用户
c 结合awk对文件进行取列
[root@linux ~]# xargs -n 2 <test01.txt|awk '{print $2}'
02
04
06
08
10
[root@linux ~]# xargs -n 2 <test01.txt|awk '{print $1}'
01
03
05
07
09
[root@linux ~]# xargs -n 2 <test01.txt|awk '{print $0}'
01 02
03 04
05 06
07 08
09 10
——2.1.2 符号 ! 的三个作用
1)强制的作用 wq!
2)可以实现取反
[root@linux ~]# awk '!/oldgirl/' test02.txt
oldboy01
oldboy02
oldboy03
oldboy04
[root@linux ~]# ll /oldboy_dir/
total 8
drwxr-xr-x 2 root root 6 Feb 4 2019 oldboy01
-rw-r--r-- 1 root root 30 Jan 16 09:16 test01.txt
-rw-r--r-- 1 root root 46 Jan 16 09:39 test02.txt
-rw-r--r-- 1 root root 0 Jan 16 09:08 test03.txt
-rw-r--r-- 1 root root 0 Jan 16 09:08 test04.txt
-rw-r--r-- 1 root root 0 Jan 16 09:08 test05.txt
[root@linux ~]# find /oldboy_dir/ ! -type f
/oldboy_dir/
/oldboy_dir/oldboy01
3)!命令 可以快速调取执行历史命令(慎用)
[root@linux ~]# !find
find /oldboy -type f -mtime -1
cat ~/.bash_history -- 记录历史命令信息, 但是不会实时记录
history -- 显示所有输入过的历史命令
history -c --删除历史命令
history -W 将内存中记录的历史命令保存到~/.bash_history文件中
ctrl + r --搜索历史命令
作用:
01. 查看你的错误操作,确认错误原因
02. 回顾高手的操作过程
——2.1.3 符号 | 的一个作用
1)实现管道功能
将前一个命令执行的结果交给管道后面的命令进行处理
一般管道符号 会经常和xargs命令配合使用
批量删除操作
find /oldboy -type f -name "oldboy*.txt"|xargs rm
find /oldboy_dir/ -type f -delete
find /oldboy_dir/ -type f -exec rm -f {} \;
1)强制的作用 wq! 2)可以实现取反 [root@linux ~]# awk '!/oldgirl/' test02.txt oldboy01 oldboy02 oldboy03 oldboy04 [root@linux ~]# ll /oldboy_dir/ total 8 drwxr-xr-x 2 root root 6 Feb 4 2019 oldboy01 -rw-r--r-- 1 root root 30 Jan 16 09:16 test01.txt -rw-r--r-- 1 root root 46 Jan 16 09:39 test02.txt -rw-r--r-- 1 root root 0 Jan 16 09:08 test03.txt -rw-r--r-- 1 root root 0 Jan 16 09:08 test04.txt -rw-r--r-- 1 root root 0 Jan 16 09:08 test05.txt [root@linux ~]# find /oldboy_dir/ ! -type f /oldboy_dir/ /oldboy_dir/oldboy01 3)!命令 可以快速调取执行历史命令(慎用) [root@linux ~]# !find find /oldboy -type f -mtime -1 cat ~/.bash_history -- 记录历史命令信息, 但是不会实时记录 history -- 显示所有输入过的历史命令 history -c --删除历史命令 history -W 将内存中记录的历史命令保存到~/.bash_history文件中 ctrl + r --搜索历史命令 作用: 01. 查看你的错误操作,确认错误原因 02. 回顾高手的操作过程
——2.1.3 符号 | 的一个作用
1)实现管道功能
将前一个命令执行的结果交给管道后面的命令进行处理
一般管道符号 会经常和xargs命令配合使用
批量删除操作
find /oldboy -type f -name "oldboy*.txt"|xargs rm
find /oldboy_dir/ -type f -delete
find /oldboy_dir/ -type f -exec rm -f {} \;
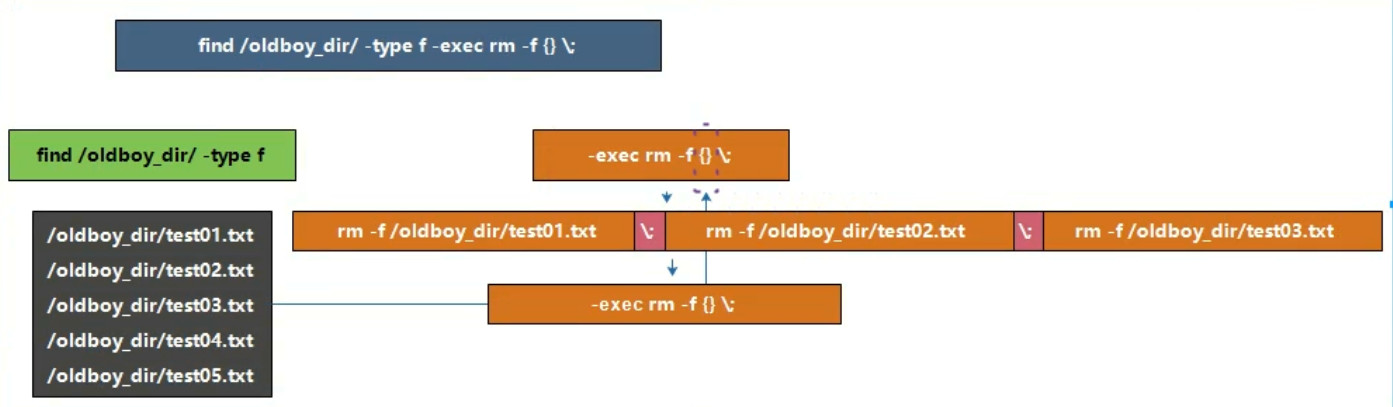
查找指定数据信息进行复制 find /oldboy -type f -name "oldboy*.txt" |xargs -i cp {} /oldgirl/ find /oldboy -type f -name "oldboy*.txt" |xargs cp -t /oldgirl/ find /oldboy -type f -name "oldboy*.txt" -exec cp -a {} /oldgirl \; 查找指定数据信息进行移动 find /oldboy -type f -name "oldboy*.txt" |xargs -i mv {} /oldgirl/ find /oldboy -type f -name "oldboy*.txt" |xargs mv -t /oldgirl/ find /oldboy -type f -name "oldboy*.txt" -exec mv {} /oldgirl \; 结论: xargs(火眼金睛)后面跟的命令,不识别别名信息 -i == input输入 -t == target目标
——2.1.4 符号 # 的两个作用
a 表示对配置文件信息进行注释
b 表示用户的身份信息 超级管理员用户
—2.2 引号符号系列
"" 基本上和单引号功能类似 但是可以对一些特殊符号做出解析
'' 里面编写的什么内容就输出什么内容 所见即所得
`` 将引号里面命令执行结果,交给引号外面命令进行使用
$ `命令` == $(命令)
作用:
01. 指定需要输出的信息
02. 利用引号将空格分隔的信息汇总为一个整体
—2.3 重定向符号
> == 1> 标准输出重定向符号
>> == 1>> 标准输出追加重定向符号
2> 错误输出重定向符号
2>> 错误输出追加重定向符号
< 标准输入重定向符号
tr xargs
<< 标准输入追加重定向符号
一条命令生成多行信息
[root@linux ~]# cat >>oldboy.txt<<oldboy
> oldgirl01
> oldgirl02
> oldgirl03
> oldboy
—2.4 逻辑符号系列
逻辑: 在完成一件事情的时候,有合理先后顺序
&& 前一个命令操作执行成功了,再操作执行后面的命令
|| 前一个命令操作执行失败了,再操作执行后面的命令
[root@linux ~]# mkdir /old_dir && echo "create dir sucess" || echo "create dir failed"
create dir sucess
[root@linux ~]# mkdi /old_dir && echo "create dir sucess" || echo "create dir failed"
-bash: mkdi: command not found
create dir failed
3. 系统通配符号waildcard
什么通配符号: 用于匹配文件名称信息, 便于快速查找文件信息 find
—3.1 符号 * 匹配所有信息
find /oldboy -type f -name "oldboy*" ---以oldboy开头的信息都查询出来
find /oldboy -type f -name "*oldboy" ---以oldboy开头的信息都查询出来
find /oldboy -type f -name "oldgirl*oldboy" ---以oldgirl 开头的信息;以oldboy 结尾的信息都查询出来
—3.2 符号 {} 产生序列信息
——3.2.1 连续序列
[root@linux ~]# echo {01..05}
01 02 03 04 05
[root@linux ~]# echo {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z
[root@linux ~]# echo {A..Z}
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
——3.2.2 生成不连续序列
a 有规律的不连续序列
[root@linux ~]# echo {01..05..2}
01 03 05
[root@linux ~]# echo {a..z..2}
a c e g i k m o q s u w y
b 没规律的不连续序列
[root@linux ~]# echo {www,bbs,blog}
www bbs blog
——3.2.3 生成组合序列
[root@linux ~]# echo {1,2}{a,b}
1a 1b 2a 2b
[root@linux ~]# echo {1,2}{a,b}{A,B}
1aA 1aB 1bA 1bB 2aA 2aB 2bA 2bB
——3.2.4 快速备份文件命令
cp oldboy.txt{,.bak} == cp oldboy.txt oldboy.txt.bak
[root@linux ~]# cp oldboy.txt{,.bak}
[root@linux ~]# ll
-rw-r--r-- 1 root root 30 Jan 16 11:12 oldboy.txt
-rw-r--r-- 1 root root 30 Jan 16 11:56 oldboy.txt.bak
——3.2.5 快速还原数据方法
[root@linux ~]# cp oldboy.txt{.bak,}
-rw-r--r-- 1 root root 30 Jan 16 12:02 oldboy.txt
-rw-r--r-- 1 root root 30 Jan 16 11:56 oldboy.txt.bak
# echo A{B,}
AB A
oldboy.txt{.bak,} == cp oldboy.txt.bak oldboy.txt
4. 系统正则符号
作用:用于结合三剑客命令用于过滤或处理编辑文件
编写模拟测试文件
cat >>~/oldboy_test.txt<<EOF
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
EOF
基础正则符号:basic regular expression (BRE)
扩展正则符号:extended regular expression (ERE)
—4.1 基础正则符号
——4.1.1 尖角符号:^
作用:以什么开头的信息进行过滤出来
需求01: 将以I开头的信息都过滤出来
[root@linux ~]# grep "^I" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
需求02: 将不是以I开头的信息都过滤出来
[root@linux ~]# grep -v "^I" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
企业需求: web服务配置文件请进行精简化处理
grep -v "^#" nginx.conf.default >nginx.conf
find / -type f -name "^oldboy" 错误
find / -type f -name "oldboy*" 正确
——4.1.2 美元符号 $
以什么结尾的信息进行过滤出来
需求01: 请找出以m结尾信息, 并且显示上1行 和 下2行的信息
[root@linux ~]# grep "m$" -A 2 -B 1 ~/oldboy_test.txt
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
错误说明:
如何确认每行结尾有空格信息
方法一:
cat -A ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com $
方法二:
vim 底行模式输入命令 --- :set list
——4.1.3 尖角美元符号 ^$
取出文件中空行信息
grep "^$" ~/oldboy_test.txt
grep -v "^$" ~/oldboy_test.txt
——4.1.4 点符号 .
表示匹配任意一个且只有一个字符
[root@linux ~]# grep "." ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "." ~/oldboy_test.txt -o
I
a
m
o
l
——4.1.5 星号符号 *
匹配星号前面一个字符连续出现1次或多次包括0次
[root@linux ~]# echo aababababb|grep "ab*" -o
a
ab
ab
ab
abb
[root@linux ~]# echo aababababb|grep "a*b*" -o
aab
ab
ab
abb
——4.1.6 点和星号组合 .*
匹配所有信息
grep ".*" ~/oldboy_test.txt
需求01: 找出以m开头的行,并且以m结尾的行,请过滤出来
[root@linux ~]# grep "^m.*m$" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
需求02: 只过滤一行中部分内容:
以m到o结束的信息
my blog is http://o
说明: 正则符号在匹配数据信息的时候具有贪婪特性
[root@linux ~]# grep "^m.*o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "^m.*/o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
说明: 避免贪婪特性的方法,实在指定一行信息中唯一节点信息
——4.1.7 转译符号 \
1) 将一些有意义的符号进行转译, 变为一个普通符号
需求: 请取出以.结尾行信息
[root@oldboy-xiaodao.com.cn ~]# grep "\.$" ~/oldboy_test.txt
I teach linux.
my qq num is 49000448.
not 4900000448.
2) 将一些没有意义的符号进行转译,变为有意义符号
\n 换行符号 linux
\r 换行符号 windows
\t 制表符号(tab)
3) 可以将扩展正则符号转换成普通正则让grep sed命令可以直接识别'
[root@linux ~]# grep "o\?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
——4.1.8 括号符号 []
匹配括号中每一个字符,并且匹配的关系是或者的关系
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# grep "oldb[oe]y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 找寻文件中字母 数字信息
[root@linux ~]# grep "[0-9a-zA-Z]" ~/oldboy_test.txt
——4.1.9 尖号和中括号组合使用 : [^]^[]
1)对中括号里面匹配的字符信息进行排除
grep "[^0-9a-zA-Z]" ~/oldboy_test.txt --- 将字母数字都排除,只留下符号信息
[root@linux ~]# grep "[^0-9a-zA-Z]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
2)尖号和中括号组合使用 : ^[]
以中括号里面匹配的字符作为一行开头的字符
[root@linux ~]# grep "^[Im]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
—4.2 正则符号注意事项
1)按照每行信息进行过滤处理
2)注意正则表达符号禁止中文
3)附上颜色信息进行正则过滤 --color=auto/--color
4)基础正则符号可以被三剑客命令直接识别 grep sed awk
5)扩展正则符号不可以被三剑客命令中老二和老三直接识别
sed命令想识别正则符号: sed -r
grep命令想识别正则符号: egrep / grep -E
—4.3 扩展正则符号
——4.3.1 加号符号 +
1)匹配加号前面一个字符连续出现1次或者多次
[root@linux ~]# egrep "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "[0-9]+" ~/oldboy_test.txt -o
51
49000448
4900000448
终极目标
cat >>~/oldboy_test02.txt<<EOF
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
EOF
问题解决方式:
[root@linux ~]# egrep -v "[0-9X]+" ~/oldboy_test02.txt
陈 oldboy
刘 oldgirl
[root@linux ~]# egrep "[^0-9X]+" ~/oldboy_test02.txt
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
——4.3.2 竖线符号:|
1)或者关系符号
[root@linux ~]# egrep "oldboy|oldbey" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 在配置文件可能有#信息,空行信息, 都要进行过滤掉不要显示
egrep -v "^#|^$" 文件名称
扩展: 如何利用sed/awk完成+/|信息过滤
1) 如何过滤数值信息
[root@linux ~]# sed -rn '/[0-9]+/p' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
[root@linux ~]# awk '/[0-9]/' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
2) 如何过滤两个字符串信息(oldboy oldbey)
[root@linux ~]# sed -nr '/oldboy|oldbey/p' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# awk '/oldboy|oldbey/' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
——4.3.3 小括号符号 ()
1)将多个字符信息进行汇总为一个整体
[root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
2)进行后向引用前向的一个操作(sed)
[root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g"
<123456>
[root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g"
<12><34><56>
企业实践应用:
01. 修改配置文件内容
[root@linux ~]# grep "^S.*UX=" /etc/selinux/config
SELINUX=disabled
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcingdisabled
[root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcing
说明: 可以将替换命令放入到脚本中,从而实现快速部署操作
02. 批量修改文件名称(作业)
oldboy01.txt
oldboy02.txt
oldboy03.txt
oldboy04.txt
oldboy05.txt
oldboy06.txt
oldboy07.txt
oldboy08.txt
oldboy09.txt
oldboy10.txt
将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
什么通配符号: 用于匹配文件名称信息, 便于快速查找文件信息 find
—3.1 符号 * 匹配所有信息
find /oldboy -type f -name "oldboy*" ---以oldboy开头的信息都查询出来 find /oldboy -type f -name "*oldboy" ---以oldboy开头的信息都查询出来 find /oldboy -type f -name "oldgirl*oldboy" ---以oldgirl 开头的信息;以oldboy 结尾的信息都查询出来
—3.2 符号 {} 产生序列信息
——3.2.1 连续序列
[root@linux ~]# echo {01..05}
01 02 03 04 05
[root@linux ~]# echo {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z
[root@linux ~]# echo {A..Z}
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
——3.2.2 生成不连续序列
a 有规律的不连续序列
[root@linux ~]# echo {01..05..2}
01 03 05
[root@linux ~]# echo {a..z..2}
a c e g i k m o q s u w y
b 没规律的不连续序列
[root@linux ~]# echo {www,bbs,blog}
www bbs blog
——3.2.3 生成组合序列
[root@linux ~]# echo {1,2}{a,b}
1a 1b 2a 2b
[root@linux ~]# echo {1,2}{a,b}{A,B}
1aA 1aB 1bA 1bB 2aA 2aB 2bA 2bB
——3.2.4 快速备份文件命令
cp oldboy.txt{,.bak} == cp oldboy.txt oldboy.txt.bak
[root@linux ~]# cp oldboy.txt{,.bak}
[root@linux ~]# ll
-rw-r--r-- 1 root root 30 Jan 16 11:12 oldboy.txt
-rw-r--r-- 1 root root 30 Jan 16 11:56 oldboy.txt.bak
——3.2.5 快速还原数据方法
[root@linux ~]# cp oldboy.txt{.bak,}
-rw-r--r-- 1 root root 30 Jan 16 12:02 oldboy.txt
-rw-r--r-- 1 root root 30 Jan 16 11:56 oldboy.txt.bak
# echo A{B,}
AB A
oldboy.txt{.bak,} == cp oldboy.txt.bak oldboy.txt
4. 系统正则符号
作用:用于结合三剑客命令用于过滤或处理编辑文件
编写模拟测试文件
cat >>~/oldboy_test.txt<<EOF
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
EOF
基础正则符号:basic regular expression (BRE)
扩展正则符号:extended regular expression (ERE)
—4.1 基础正则符号
——4.1.1 尖角符号:^
作用:以什么开头的信息进行过滤出来
需求01: 将以I开头的信息都过滤出来
[root@linux ~]# grep "^I" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
需求02: 将不是以I开头的信息都过滤出来
[root@linux ~]# grep -v "^I" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
企业需求: web服务配置文件请进行精简化处理
grep -v "^#" nginx.conf.default >nginx.conf
find / -type f -name "^oldboy" 错误
find / -type f -name "oldboy*" 正确
——4.1.2 美元符号 $
以什么结尾的信息进行过滤出来
需求01: 请找出以m结尾信息, 并且显示上1行 和 下2行的信息
[root@linux ~]# grep "m$" -A 2 -B 1 ~/oldboy_test.txt
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
错误说明:
如何确认每行结尾有空格信息
方法一:
cat -A ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com $
方法二:
vim 底行模式输入命令 --- :set list
——4.1.3 尖角美元符号 ^$
取出文件中空行信息
grep "^$" ~/oldboy_test.txt
grep -v "^$" ~/oldboy_test.txt
——4.1.4 点符号 .
表示匹配任意一个且只有一个字符
[root@linux ~]# grep "." ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "." ~/oldboy_test.txt -o
I
a
m
o
l
——4.1.5 星号符号 *
匹配星号前面一个字符连续出现1次或多次包括0次
[root@linux ~]# echo aababababb|grep "ab*" -o
a
ab
ab
ab
abb
[root@linux ~]# echo aababababb|grep "a*b*" -o
aab
ab
ab
abb
——4.1.6 点和星号组合 .*
匹配所有信息
grep ".*" ~/oldboy_test.txt
需求01: 找出以m开头的行,并且以m结尾的行,请过滤出来
[root@linux ~]# grep "^m.*m$" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
需求02: 只过滤一行中部分内容:
以m到o结束的信息
my blog is http://o
说明: 正则符号在匹配数据信息的时候具有贪婪特性
[root@linux ~]# grep "^m.*o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "^m.*/o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
说明: 避免贪婪特性的方法,实在指定一行信息中唯一节点信息
——4.1.7 转译符号 \
1) 将一些有意义的符号进行转译, 变为一个普通符号
需求: 请取出以.结尾行信息
[root@oldboy-xiaodao.com.cn ~]# grep "\.$" ~/oldboy_test.txt
I teach linux.
my qq num is 49000448.
not 4900000448.
2) 将一些没有意义的符号进行转译,变为有意义符号
\n 换行符号 linux
\r 换行符号 windows
\t 制表符号(tab)
3) 可以将扩展正则符号转换成普通正则让grep sed命令可以直接识别'
[root@linux ~]# grep "o\?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
——4.1.8 括号符号 []
匹配括号中每一个字符,并且匹配的关系是或者的关系
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# grep "oldb[oe]y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 找寻文件中字母 数字信息
[root@linux ~]# grep "[0-9a-zA-Z]" ~/oldboy_test.txt
——4.1.9 尖号和中括号组合使用 : [^]^[]
1)对中括号里面匹配的字符信息进行排除
grep "[^0-9a-zA-Z]" ~/oldboy_test.txt --- 将字母数字都排除,只留下符号信息
[root@linux ~]# grep "[^0-9a-zA-Z]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
2)尖号和中括号组合使用 : ^[]
以中括号里面匹配的字符作为一行开头的字符
[root@linux ~]# grep "^[Im]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
—4.2 正则符号注意事项
1)按照每行信息进行过滤处理
2)注意正则表达符号禁止中文
3)附上颜色信息进行正则过滤 --color=auto/--color
4)基础正则符号可以被三剑客命令直接识别 grep sed awk
5)扩展正则符号不可以被三剑客命令中老二和老三直接识别
sed命令想识别正则符号: sed -r
grep命令想识别正则符号: egrep / grep -E
—4.3 扩展正则符号
——4.3.1 加号符号 +
1)匹配加号前面一个字符连续出现1次或者多次
[root@linux ~]# egrep "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "[0-9]+" ~/oldboy_test.txt -o
51
49000448
4900000448
终极目标
cat >>~/oldboy_test02.txt<<EOF
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
EOF
问题解决方式:
[root@linux ~]# egrep -v "[0-9X]+" ~/oldboy_test02.txt
陈 oldboy
刘 oldgirl
[root@linux ~]# egrep "[^0-9X]+" ~/oldboy_test02.txt
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
——4.3.2 竖线符号:|
1)或者关系符号
[root@linux ~]# egrep "oldboy|oldbey" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 在配置文件可能有#信息,空行信息, 都要进行过滤掉不要显示
egrep -v "^#|^$" 文件名称
扩展: 如何利用sed/awk完成+/|信息过滤
1) 如何过滤数值信息
[root@linux ~]# sed -rn '/[0-9]+/p' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
[root@linux ~]# awk '/[0-9]/' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
2) 如何过滤两个字符串信息(oldboy oldbey)
[root@linux ~]# sed -nr '/oldboy|oldbey/p' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# awk '/oldboy|oldbey/' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
——4.3.3 小括号符号 ()
1)将多个字符信息进行汇总为一个整体
[root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
2)进行后向引用前向的一个操作(sed)
[root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g"
<123456>
[root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g"
<12><34><56>
企业实践应用:
01. 修改配置文件内容
[root@linux ~]# grep "^S.*UX=" /etc/selinux/config
SELINUX=disabled
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcingdisabled
[root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcing
说明: 可以将替换命令放入到脚本中,从而实现快速部署操作
02. 批量修改文件名称(作业)
oldboy01.txt
oldboy02.txt
oldboy03.txt
oldboy04.txt
oldboy05.txt
oldboy06.txt
oldboy07.txt
oldboy08.txt
oldboy09.txt
oldboy10.txt
将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
a 有规律的不连续序列 [root@linux ~]# echo {01..05..2} 01 03 05 [root@linux ~]# echo {a..z..2} a c e g i k m o q s u w y b 没规律的不连续序列 [root@linux ~]# echo {www,bbs,blog} www bbs blog
——3.2.3 生成组合序列
[root@linux ~]# echo {1,2}{a,b}
1a 1b 2a 2b
[root@linux ~]# echo {1,2}{a,b}{A,B}
1aA 1aB 1bA 1bB 2aA 2aB 2bA 2bB
——3.2.4 快速备份文件命令
cp oldboy.txt{,.bak} == cp oldboy.txt oldboy.txt.bak
[root@linux ~]# cp oldboy.txt{,.bak}
[root@linux ~]# ll
-rw-r--r-- 1 root root 30 Jan 16 11:12 oldboy.txt
-rw-r--r-- 1 root root 30 Jan 16 11:56 oldboy.txt.bak
——3.2.5 快速还原数据方法
[root@linux ~]# cp oldboy.txt{.bak,}
-rw-r--r-- 1 root root 30 Jan 16 12:02 oldboy.txt
-rw-r--r-- 1 root root 30 Jan 16 11:56 oldboy.txt.bak
# echo A{B,}
AB A
oldboy.txt{.bak,} == cp oldboy.txt.bak oldboy.txt
4. 系统正则符号
作用:用于结合三剑客命令用于过滤或处理编辑文件
编写模拟测试文件
cat >>~/oldboy_test.txt<<EOF
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
EOF
基础正则符号:basic regular expression (BRE)
扩展正则符号:extended regular expression (ERE)
—4.1 基础正则符号
——4.1.1 尖角符号:^
作用:以什么开头的信息进行过滤出来
需求01: 将以I开头的信息都过滤出来
[root@linux ~]# grep "^I" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
需求02: 将不是以I开头的信息都过滤出来
[root@linux ~]# grep -v "^I" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
企业需求: web服务配置文件请进行精简化处理
grep -v "^#" nginx.conf.default >nginx.conf
find / -type f -name "^oldboy" 错误
find / -type f -name "oldboy*" 正确
——4.1.2 美元符号 $
以什么结尾的信息进行过滤出来
需求01: 请找出以m结尾信息, 并且显示上1行 和 下2行的信息
[root@linux ~]# grep "m$" -A 2 -B 1 ~/oldboy_test.txt
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
错误说明:
如何确认每行结尾有空格信息
方法一:
cat -A ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com $
方法二:
vim 底行模式输入命令 --- :set list
——4.1.3 尖角美元符号 ^$
取出文件中空行信息
grep "^$" ~/oldboy_test.txt
grep -v "^$" ~/oldboy_test.txt
——4.1.4 点符号 .
表示匹配任意一个且只有一个字符
[root@linux ~]# grep "." ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "." ~/oldboy_test.txt -o
I
a
m
o
l
——4.1.5 星号符号 *
匹配星号前面一个字符连续出现1次或多次包括0次
[root@linux ~]# echo aababababb|grep "ab*" -o
a
ab
ab
ab
abb
[root@linux ~]# echo aababababb|grep "a*b*" -o
aab
ab
ab
abb
——4.1.6 点和星号组合 .*
匹配所有信息
grep ".*" ~/oldboy_test.txt
需求01: 找出以m开头的行,并且以m结尾的行,请过滤出来
[root@linux ~]# grep "^m.*m$" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
需求02: 只过滤一行中部分内容:
以m到o结束的信息
my blog is http://o
说明: 正则符号在匹配数据信息的时候具有贪婪特性
[root@linux ~]# grep "^m.*o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "^m.*/o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
说明: 避免贪婪特性的方法,实在指定一行信息中唯一节点信息
——4.1.7 转译符号 \
1) 将一些有意义的符号进行转译, 变为一个普通符号
需求: 请取出以.结尾行信息
[root@oldboy-xiaodao.com.cn ~]# grep "\.$" ~/oldboy_test.txt
I teach linux.
my qq num is 49000448.
not 4900000448.
2) 将一些没有意义的符号进行转译,变为有意义符号
\n 换行符号 linux
\r 换行符号 windows
\t 制表符号(tab)
3) 可以将扩展正则符号转换成普通正则让grep sed命令可以直接识别'
[root@linux ~]# grep "o\?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
——4.1.8 括号符号 []
匹配括号中每一个字符,并且匹配的关系是或者的关系
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# grep "oldb[oe]y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 找寻文件中字母 数字信息
[root@linux ~]# grep "[0-9a-zA-Z]" ~/oldboy_test.txt
——4.1.9 尖号和中括号组合使用 : [^]^[]
1)对中括号里面匹配的字符信息进行排除
grep "[^0-9a-zA-Z]" ~/oldboy_test.txt --- 将字母数字都排除,只留下符号信息
[root@linux ~]# grep "[^0-9a-zA-Z]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
2)尖号和中括号组合使用 : ^[]
以中括号里面匹配的字符作为一行开头的字符
[root@linux ~]# grep "^[Im]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
—4.2 正则符号注意事项
1)按照每行信息进行过滤处理
2)注意正则表达符号禁止中文
3)附上颜色信息进行正则过滤 --color=auto/--color
4)基础正则符号可以被三剑客命令直接识别 grep sed awk
5)扩展正则符号不可以被三剑客命令中老二和老三直接识别
sed命令想识别正则符号: sed -r
grep命令想识别正则符号: egrep / grep -E
—4.3 扩展正则符号
——4.3.1 加号符号 +
1)匹配加号前面一个字符连续出现1次或者多次
[root@linux ~]# egrep "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "[0-9]+" ~/oldboy_test.txt -o
51
49000448
4900000448
终极目标
cat >>~/oldboy_test02.txt<<EOF
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
EOF
问题解决方式:
[root@linux ~]# egrep -v "[0-9X]+" ~/oldboy_test02.txt
陈 oldboy
刘 oldgirl
[root@linux ~]# egrep "[^0-9X]+" ~/oldboy_test02.txt
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
——4.3.2 竖线符号:|
1)或者关系符号
[root@linux ~]# egrep "oldboy|oldbey" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 在配置文件可能有#信息,空行信息, 都要进行过滤掉不要显示
egrep -v "^#|^$" 文件名称
扩展: 如何利用sed/awk完成+/|信息过滤
1) 如何过滤数值信息
[root@linux ~]# sed -rn '/[0-9]+/p' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
[root@linux ~]# awk '/[0-9]/' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
2) 如何过滤两个字符串信息(oldboy oldbey)
[root@linux ~]# sed -nr '/oldboy|oldbey/p' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# awk '/oldboy|oldbey/' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
——4.3.3 小括号符号 ()
1)将多个字符信息进行汇总为一个整体
[root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
2)进行后向引用前向的一个操作(sed)
[root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g"
<123456>
[root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g"
<12><34><56>
企业实践应用:
01. 修改配置文件内容
[root@linux ~]# grep "^S.*UX=" /etc/selinux/config
SELINUX=disabled
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcingdisabled
[root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcing
说明: 可以将替换命令放入到脚本中,从而实现快速部署操作
02. 批量修改文件名称(作业)
oldboy01.txt
oldboy02.txt
oldboy03.txt
oldboy04.txt
oldboy05.txt
oldboy06.txt
oldboy07.txt
oldboy08.txt
oldboy09.txt
oldboy10.txt
将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
cp oldboy.txt{,.bak} == cp oldboy.txt oldboy.txt.bak [root@linux ~]# cp oldboy.txt{,.bak} [root@linux ~]# ll -rw-r--r-- 1 root root 30 Jan 16 11:12 oldboy.txt -rw-r--r-- 1 root root 30 Jan 16 11:56 oldboy.txt.bak
——3.2.5 快速还原数据方法
[root@linux ~]# cp oldboy.txt{.bak,}
-rw-r--r-- 1 root root 30 Jan 16 12:02 oldboy.txt
-rw-r--r-- 1 root root 30 Jan 16 11:56 oldboy.txt.bak
# echo A{B,}
AB A
oldboy.txt{.bak,} == cp oldboy.txt.bak oldboy.txt
4. 系统正则符号
作用:用于结合三剑客命令用于过滤或处理编辑文件
编写模拟测试文件
cat >>~/oldboy_test.txt<<EOF
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
EOF
基础正则符号:basic regular expression (BRE)
扩展正则符号:extended regular expression (ERE)
—4.1 基础正则符号
——4.1.1 尖角符号:^
作用:以什么开头的信息进行过滤出来
需求01: 将以I开头的信息都过滤出来
[root@linux ~]# grep "^I" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
需求02: 将不是以I开头的信息都过滤出来
[root@linux ~]# grep -v "^I" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
企业需求: web服务配置文件请进行精简化处理
grep -v "^#" nginx.conf.default >nginx.conf
find / -type f -name "^oldboy" 错误
find / -type f -name "oldboy*" 正确
——4.1.2 美元符号 $
以什么结尾的信息进行过滤出来
需求01: 请找出以m结尾信息, 并且显示上1行 和 下2行的信息
[root@linux ~]# grep "m$" -A 2 -B 1 ~/oldboy_test.txt
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
错误说明:
如何确认每行结尾有空格信息
方法一:
cat -A ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com $
方法二:
vim 底行模式输入命令 --- :set list
——4.1.3 尖角美元符号 ^$
取出文件中空行信息
grep "^$" ~/oldboy_test.txt
grep -v "^$" ~/oldboy_test.txt
——4.1.4 点符号 .
表示匹配任意一个且只有一个字符
[root@linux ~]# grep "." ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "." ~/oldboy_test.txt -o
I
a
m
o
l
——4.1.5 星号符号 *
匹配星号前面一个字符连续出现1次或多次包括0次
[root@linux ~]# echo aababababb|grep "ab*" -o
a
ab
ab
ab
abb
[root@linux ~]# echo aababababb|grep "a*b*" -o
aab
ab
ab
abb
——4.1.6 点和星号组合 .*
匹配所有信息
grep ".*" ~/oldboy_test.txt
需求01: 找出以m开头的行,并且以m结尾的行,请过滤出来
[root@linux ~]# grep "^m.*m$" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
需求02: 只过滤一行中部分内容:
以m到o结束的信息
my blog is http://o
说明: 正则符号在匹配数据信息的时候具有贪婪特性
[root@linux ~]# grep "^m.*o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "^m.*/o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
说明: 避免贪婪特性的方法,实在指定一行信息中唯一节点信息
——4.1.7 转译符号 \
1) 将一些有意义的符号进行转译, 变为一个普通符号
需求: 请取出以.结尾行信息
[root@oldboy-xiaodao.com.cn ~]# grep "\.$" ~/oldboy_test.txt
I teach linux.
my qq num is 49000448.
not 4900000448.
2) 将一些没有意义的符号进行转译,变为有意义符号
\n 换行符号 linux
\r 换行符号 windows
\t 制表符号(tab)
3) 可以将扩展正则符号转换成普通正则让grep sed命令可以直接识别'
[root@linux ~]# grep "o\?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
——4.1.8 括号符号 []
匹配括号中每一个字符,并且匹配的关系是或者的关系
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# grep "oldb[oe]y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 找寻文件中字母 数字信息
[root@linux ~]# grep "[0-9a-zA-Z]" ~/oldboy_test.txt
——4.1.9 尖号和中括号组合使用 : [^]^[]
1)对中括号里面匹配的字符信息进行排除
grep "[^0-9a-zA-Z]" ~/oldboy_test.txt --- 将字母数字都排除,只留下符号信息
[root@linux ~]# grep "[^0-9a-zA-Z]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
2)尖号和中括号组合使用 : ^[]
以中括号里面匹配的字符作为一行开头的字符
[root@linux ~]# grep "^[Im]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
—4.2 正则符号注意事项
1)按照每行信息进行过滤处理
2)注意正则表达符号禁止中文
3)附上颜色信息进行正则过滤 --color=auto/--color
4)基础正则符号可以被三剑客命令直接识别 grep sed awk
5)扩展正则符号不可以被三剑客命令中老二和老三直接识别
sed命令想识别正则符号: sed -r
grep命令想识别正则符号: egrep / grep -E
—4.3 扩展正则符号
——4.3.1 加号符号 +
1)匹配加号前面一个字符连续出现1次或者多次
[root@linux ~]# egrep "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "[0-9]+" ~/oldboy_test.txt -o
51
49000448
4900000448
终极目标
cat >>~/oldboy_test02.txt<<EOF
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
EOF
问题解决方式:
[root@linux ~]# egrep -v "[0-9X]+" ~/oldboy_test02.txt
陈 oldboy
刘 oldgirl
[root@linux ~]# egrep "[^0-9X]+" ~/oldboy_test02.txt
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
——4.3.2 竖线符号:|
1)或者关系符号
[root@linux ~]# egrep "oldboy|oldbey" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 在配置文件可能有#信息,空行信息, 都要进行过滤掉不要显示
egrep -v "^#|^$" 文件名称
扩展: 如何利用sed/awk完成+/|信息过滤
1) 如何过滤数值信息
[root@linux ~]# sed -rn '/[0-9]+/p' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
[root@linux ~]# awk '/[0-9]/' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
2) 如何过滤两个字符串信息(oldboy oldbey)
[root@linux ~]# sed -nr '/oldboy|oldbey/p' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# awk '/oldboy|oldbey/' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
——4.3.3 小括号符号 ()
1)将多个字符信息进行汇总为一个整体
[root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
2)进行后向引用前向的一个操作(sed)
[root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g"
<123456>
[root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g"
<12><34><56>
企业实践应用:
01. 修改配置文件内容
[root@linux ~]# grep "^S.*UX=" /etc/selinux/config
SELINUX=disabled
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcingdisabled
[root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcing
说明: 可以将替换命令放入到脚本中,从而实现快速部署操作
02. 批量修改文件名称(作业)
oldboy01.txt
oldboy02.txt
oldboy03.txt
oldboy04.txt
oldboy05.txt
oldboy06.txt
oldboy07.txt
oldboy08.txt
oldboy09.txt
oldboy10.txt
将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
作用:用于结合三剑客命令用于过滤或处理编辑文件 编写模拟测试文件 cat >>~/oldboy_test.txt<<EOF I am oldboy teacher! I teach linux. I like badminton ball ,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our site is http://www.etiantian.org my qq num is 49000448. not 4900000448. my god ,i am not oldbey,but OLDBOY! EOF 基础正则符号:basic regular expression (BRE) 扩展正则符号:extended regular expression (ERE)
—4.1 基础正则符号
——4.1.1 尖角符号:^
作用:以什么开头的信息进行过滤出来
需求01: 将以I开头的信息都过滤出来
[root@linux ~]# grep "^I" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
需求02: 将不是以I开头的信息都过滤出来
[root@linux ~]# grep -v "^I" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
企业需求: web服务配置文件请进行精简化处理
grep -v "^#" nginx.conf.default >nginx.conf
find / -type f -name "^oldboy" 错误
find / -type f -name "oldboy*" 正确
——4.1.2 美元符号 $
以什么结尾的信息进行过滤出来
需求01: 请找出以m结尾信息, 并且显示上1行 和 下2行的信息
[root@linux ~]# grep "m$" -A 2 -B 1 ~/oldboy_test.txt
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
错误说明:
如何确认每行结尾有空格信息
方法一:
cat -A ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com $
方法二:
vim 底行模式输入命令 --- :set list
——4.1.3 尖角美元符号 ^$
取出文件中空行信息
grep "^$" ~/oldboy_test.txt
grep -v "^$" ~/oldboy_test.txt
——4.1.4 点符号 .
表示匹配任意一个且只有一个字符
[root@linux ~]# grep "." ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "." ~/oldboy_test.txt -o
I
a
m
o
l
——4.1.5 星号符号 *
匹配星号前面一个字符连续出现1次或多次包括0次
[root@linux ~]# echo aababababb|grep "ab*" -o
a
ab
ab
ab
abb
[root@linux ~]# echo aababababb|grep "a*b*" -o
aab
ab
ab
abb
——4.1.6 点和星号组合 .*
匹配所有信息
grep ".*" ~/oldboy_test.txt
需求01: 找出以m开头的行,并且以m结尾的行,请过滤出来
[root@linux ~]# grep "^m.*m$" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
需求02: 只过滤一行中部分内容:
以m到o结束的信息
my blog is http://o
说明: 正则符号在匹配数据信息的时候具有贪婪特性
[root@linux ~]# grep "^m.*o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "^m.*/o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
说明: 避免贪婪特性的方法,实在指定一行信息中唯一节点信息
——4.1.7 转译符号 \
1) 将一些有意义的符号进行转译, 变为一个普通符号
需求: 请取出以.结尾行信息
[root@oldboy-xiaodao.com.cn ~]# grep "\.$" ~/oldboy_test.txt
I teach linux.
my qq num is 49000448.
not 4900000448.
2) 将一些没有意义的符号进行转译,变为有意义符号
\n 换行符号 linux
\r 换行符号 windows
\t 制表符号(tab)
3) 可以将扩展正则符号转换成普通正则让grep sed命令可以直接识别'
[root@linux ~]# grep "o\?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
——4.1.8 括号符号 []
匹配括号中每一个字符,并且匹配的关系是或者的关系
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# grep "oldb[oe]y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 找寻文件中字母 数字信息
[root@linux ~]# grep "[0-9a-zA-Z]" ~/oldboy_test.txt
——4.1.9 尖号和中括号组合使用 : [^]^[]
1)对中括号里面匹配的字符信息进行排除
grep "[^0-9a-zA-Z]" ~/oldboy_test.txt --- 将字母数字都排除,只留下符号信息
[root@linux ~]# grep "[^0-9a-zA-Z]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
2)尖号和中括号组合使用 : ^[]
以中括号里面匹配的字符作为一行开头的字符
[root@linux ~]# grep "^[Im]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
—4.2 正则符号注意事项
1)按照每行信息进行过滤处理
2)注意正则表达符号禁止中文
3)附上颜色信息进行正则过滤 --color=auto/--color
4)基础正则符号可以被三剑客命令直接识别 grep sed awk
5)扩展正则符号不可以被三剑客命令中老二和老三直接识别
sed命令想识别正则符号: sed -r
grep命令想识别正则符号: egrep / grep -E
—4.3 扩展正则符号
——4.3.1 加号符号 +
1)匹配加号前面一个字符连续出现1次或者多次
[root@linux ~]# egrep "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "[0-9]+" ~/oldboy_test.txt -o
51
49000448
4900000448
终极目标
cat >>~/oldboy_test02.txt<<EOF
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
EOF
问题解决方式:
[root@linux ~]# egrep -v "[0-9X]+" ~/oldboy_test02.txt
陈 oldboy
刘 oldgirl
[root@linux ~]# egrep "[^0-9X]+" ~/oldboy_test02.txt
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
——4.3.2 竖线符号:|
1)或者关系符号
[root@linux ~]# egrep "oldboy|oldbey" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 在配置文件可能有#信息,空行信息, 都要进行过滤掉不要显示
egrep -v "^#|^$" 文件名称
扩展: 如何利用sed/awk完成+/|信息过滤
1) 如何过滤数值信息
[root@linux ~]# sed -rn '/[0-9]+/p' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
[root@linux ~]# awk '/[0-9]/' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
2) 如何过滤两个字符串信息(oldboy oldbey)
[root@linux ~]# sed -nr '/oldboy|oldbey/p' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# awk '/oldboy|oldbey/' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
——4.3.3 小括号符号 ()
1)将多个字符信息进行汇总为一个整体
[root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
2)进行后向引用前向的一个操作(sed)
[root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g"
<123456>
[root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g"
<12><34><56>
企业实践应用:
01. 修改配置文件内容
[root@linux ~]# grep "^S.*UX=" /etc/selinux/config
SELINUX=disabled
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcingdisabled
[root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcing
说明: 可以将替换命令放入到脚本中,从而实现快速部署操作
02. 批量修改文件名称(作业)
oldboy01.txt
oldboy02.txt
oldboy03.txt
oldboy04.txt
oldboy05.txt
oldboy06.txt
oldboy07.txt
oldboy08.txt
oldboy09.txt
oldboy10.txt
将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
以什么结尾的信息进行过滤出来 需求01: 请找出以m结尾信息, 并且显示上1行 和 下2行的信息 [root@linux ~]# grep "m$" -A 2 -B 1 ~/oldboy_test.txt I like badminton ball ,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our site is http://www.etiantian.org my qq num is 49000448. 错误说明: 如何确认每行结尾有空格信息 方法一: cat -A ~/oldboy_test.txt my blog is http://oldboy.blog.51cto.com $ 方法二: vim 底行模式输入命令 --- :set list
——4.1.3 尖角美元符号 ^$
取出文件中空行信息
grep "^$" ~/oldboy_test.txt
grep -v "^$" ~/oldboy_test.txt
——4.1.4 点符号 .
表示匹配任意一个且只有一个字符
[root@linux ~]# grep "." ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "." ~/oldboy_test.txt -o
I
a
m
o
l
——4.1.5 星号符号 *
匹配星号前面一个字符连续出现1次或多次包括0次
[root@linux ~]# echo aababababb|grep "ab*" -o
a
ab
ab
ab
abb
[root@linux ~]# echo aababababb|grep "a*b*" -o
aab
ab
ab
abb
——4.1.6 点和星号组合 .*
匹配所有信息
grep ".*" ~/oldboy_test.txt
需求01: 找出以m开头的行,并且以m结尾的行,请过滤出来
[root@linux ~]# grep "^m.*m$" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
需求02: 只过滤一行中部分内容:
以m到o结束的信息
my blog is http://o
说明: 正则符号在匹配数据信息的时候具有贪婪特性
[root@linux ~]# grep "^m.*o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "^m.*/o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
说明: 避免贪婪特性的方法,实在指定一行信息中唯一节点信息
——4.1.7 转译符号 \
1) 将一些有意义的符号进行转译, 变为一个普通符号
需求: 请取出以.结尾行信息
[root@oldboy-xiaodao.com.cn ~]# grep "\.$" ~/oldboy_test.txt
I teach linux.
my qq num is 49000448.
not 4900000448.
2) 将一些没有意义的符号进行转译,变为有意义符号
\n 换行符号 linux
\r 换行符号 windows
\t 制表符号(tab)
3) 可以将扩展正则符号转换成普通正则让grep sed命令可以直接识别'
[root@linux ~]# grep "o\?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
——4.1.8 括号符号 []
匹配括号中每一个字符,并且匹配的关系是或者的关系
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# grep "oldb[oe]y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 找寻文件中字母 数字信息
[root@linux ~]# grep "[0-9a-zA-Z]" ~/oldboy_test.txt
——4.1.9 尖号和中括号组合使用 : [^]^[]
1)对中括号里面匹配的字符信息进行排除
grep "[^0-9a-zA-Z]" ~/oldboy_test.txt --- 将字母数字都排除,只留下符号信息
[root@linux ~]# grep "[^0-9a-zA-Z]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
2)尖号和中括号组合使用 : ^[]
以中括号里面匹配的字符作为一行开头的字符
[root@linux ~]# grep "^[Im]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
—4.2 正则符号注意事项
1)按照每行信息进行过滤处理
2)注意正则表达符号禁止中文
3)附上颜色信息进行正则过滤 --color=auto/--color
4)基础正则符号可以被三剑客命令直接识别 grep sed awk
5)扩展正则符号不可以被三剑客命令中老二和老三直接识别
sed命令想识别正则符号: sed -r
grep命令想识别正则符号: egrep / grep -E
—4.3 扩展正则符号
——4.3.1 加号符号 +
1)匹配加号前面一个字符连续出现1次或者多次
[root@linux ~]# egrep "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "[0-9]+" ~/oldboy_test.txt -o
51
49000448
4900000448
终极目标
cat >>~/oldboy_test02.txt<<EOF
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
EOF
问题解决方式:
[root@linux ~]# egrep -v "[0-9X]+" ~/oldboy_test02.txt
陈 oldboy
刘 oldgirl
[root@linux ~]# egrep "[^0-9X]+" ~/oldboy_test02.txt
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
——4.3.2 竖线符号:|
1)或者关系符号
[root@linux ~]# egrep "oldboy|oldbey" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 在配置文件可能有#信息,空行信息, 都要进行过滤掉不要显示
egrep -v "^#|^$" 文件名称
扩展: 如何利用sed/awk完成+/|信息过滤
1) 如何过滤数值信息
[root@linux ~]# sed -rn '/[0-9]+/p' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
[root@linux ~]# awk '/[0-9]/' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
2) 如何过滤两个字符串信息(oldboy oldbey)
[root@linux ~]# sed -nr '/oldboy|oldbey/p' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# awk '/oldboy|oldbey/' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
——4.3.3 小括号符号 ()
1)将多个字符信息进行汇总为一个整体
[root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
2)进行后向引用前向的一个操作(sed)
[root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g"
<123456>
[root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g"
<12><34><56>
企业实践应用:
01. 修改配置文件内容
[root@linux ~]# grep "^S.*UX=" /etc/selinux/config
SELINUX=disabled
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcingdisabled
[root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcing
说明: 可以将替换命令放入到脚本中,从而实现快速部署操作
02. 批量修改文件名称(作业)
oldboy01.txt
oldboy02.txt
oldboy03.txt
oldboy04.txt
oldboy05.txt
oldboy06.txt
oldboy07.txt
oldboy08.txt
oldboy09.txt
oldboy10.txt
将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
表示匹配任意一个且只有一个字符 [root@linux ~]# grep "." ~/oldboy_test.txt I am oldboy teacher! I teach linux. I like badminton ball ,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our site is http://www.etiantian.org my qq num is 49000448. not 4900000448. my god ,i am not oldbey,but OLDBOY! [root@linux ~]# grep "." ~/oldboy_test.txt -o I a m o l
——4.1.5 星号符号 *
匹配星号前面一个字符连续出现1次或多次包括0次
[root@linux ~]# echo aababababb|grep "ab*" -o
a
ab
ab
ab
abb
[root@linux ~]# echo aababababb|grep "a*b*" -o
aab
ab
ab
abb
——4.1.6 点和星号组合 .*
匹配所有信息
grep ".*" ~/oldboy_test.txt
需求01: 找出以m开头的行,并且以m结尾的行,请过滤出来
[root@linux ~]# grep "^m.*m$" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
需求02: 只过滤一行中部分内容:
以m到o结束的信息
my blog is http://o
说明: 正则符号在匹配数据信息的时候具有贪婪特性
[root@linux ~]# grep "^m.*o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# grep "^m.*/o" ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
说明: 避免贪婪特性的方法,实在指定一行信息中唯一节点信息
——4.1.7 转译符号 \
1) 将一些有意义的符号进行转译, 变为一个普通符号
需求: 请取出以.结尾行信息
[root@oldboy-xiaodao.com.cn ~]# grep "\.$" ~/oldboy_test.txt
I teach linux.
my qq num is 49000448.
not 4900000448.
2) 将一些没有意义的符号进行转译,变为有意义符号
\n 换行符号 linux
\r 换行符号 windows
\t 制表符号(tab)
3) 可以将扩展正则符号转换成普通正则让grep sed命令可以直接识别'
[root@linux ~]# grep "o\?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
——4.1.8 括号符号 []
匹配括号中每一个字符,并且匹配的关系是或者的关系
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# grep "oldb[oe]y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 找寻文件中字母 数字信息
[root@linux ~]# grep "[0-9a-zA-Z]" ~/oldboy_test.txt
——4.1.9 尖号和中括号组合使用 : [^]^[]
1)对中括号里面匹配的字符信息进行排除
grep "[^0-9a-zA-Z]" ~/oldboy_test.txt --- 将字母数字都排除,只留下符号信息
[root@linux ~]# grep "[^0-9a-zA-Z]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
2)尖号和中括号组合使用 : ^[]
以中括号里面匹配的字符作为一行开头的字符
[root@linux ~]# grep "^[Im]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
—4.2 正则符号注意事项
1)按照每行信息进行过滤处理
2)注意正则表达符号禁止中文
3)附上颜色信息进行正则过滤 --color=auto/--color
4)基础正则符号可以被三剑客命令直接识别 grep sed awk
5)扩展正则符号不可以被三剑客命令中老二和老三直接识别
sed命令想识别正则符号: sed -r
grep命令想识别正则符号: egrep / grep -E
—4.3 扩展正则符号
——4.3.1 加号符号 +
1)匹配加号前面一个字符连续出现1次或者多次
[root@linux ~]# egrep "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "[0-9]+" ~/oldboy_test.txt -o
51
49000448
4900000448
终极目标
cat >>~/oldboy_test02.txt<<EOF
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
EOF
问题解决方式:
[root@linux ~]# egrep -v "[0-9X]+" ~/oldboy_test02.txt
陈 oldboy
刘 oldgirl
[root@linux ~]# egrep "[^0-9X]+" ~/oldboy_test02.txt
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
——4.3.2 竖线符号:|
1)或者关系符号
[root@linux ~]# egrep "oldboy|oldbey" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 在配置文件可能有#信息,空行信息, 都要进行过滤掉不要显示
egrep -v "^#|^$" 文件名称
扩展: 如何利用sed/awk完成+/|信息过滤
1) 如何过滤数值信息
[root@linux ~]# sed -rn '/[0-9]+/p' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
[root@linux ~]# awk '/[0-9]/' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
2) 如何过滤两个字符串信息(oldboy oldbey)
[root@linux ~]# sed -nr '/oldboy|oldbey/p' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# awk '/oldboy|oldbey/' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
——4.3.3 小括号符号 ()
1)将多个字符信息进行汇总为一个整体
[root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
2)进行后向引用前向的一个操作(sed)
[root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g"
<123456>
[root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g"
<12><34><56>
企业实践应用:
01. 修改配置文件内容
[root@linux ~]# grep "^S.*UX=" /etc/selinux/config
SELINUX=disabled
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcingdisabled
[root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcing
说明: 可以将替换命令放入到脚本中,从而实现快速部署操作
02. 批量修改文件名称(作业)
oldboy01.txt
oldboy02.txt
oldboy03.txt
oldboy04.txt
oldboy05.txt
oldboy06.txt
oldboy07.txt
oldboy08.txt
oldboy09.txt
oldboy10.txt
将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
匹配所有信息 grep ".*" ~/oldboy_test.txt 需求01: 找出以m开头的行,并且以m结尾的行,请过滤出来 [root@linux ~]# grep "^m.*m$" ~/oldboy_test.txt my blog is http://oldboy.blog.51cto.com 需求02: 只过滤一行中部分内容: 以m到o结束的信息 my blog is http://o 说明: 正则符号在匹配数据信息的时候具有贪婪特性 [root@linux ~]# grep "^m.*o" ~/oldboy_test.txt my blog is http://oldboy.blog.51cto.com my god ,i am not oldbey,but OLDBOY! [root@linux ~]# grep "^m.*/o" ~/oldboy_test.txt my blog is http://oldboy.blog.51cto.com 说明: 避免贪婪特性的方法,实在指定一行信息中唯一节点信息
——4.1.7 转译符号 \
1) 将一些有意义的符号进行转译, 变为一个普通符号
需求: 请取出以.结尾行信息
[root@oldboy-xiaodao.com.cn ~]# grep "\.$" ~/oldboy_test.txt
I teach linux.
my qq num is 49000448.
not 4900000448.
2) 将一些没有意义的符号进行转译,变为有意义符号
\n 换行符号 linux
\r 换行符号 windows
\t 制表符号(tab)
3) 可以将扩展正则符号转换成普通正则让grep sed命令可以直接识别'
[root@linux ~]# grep "o\?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
——4.1.8 括号符号 []
匹配括号中每一个字符,并且匹配的关系是或者的关系
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# grep "oldb[oe]y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 找寻文件中字母 数字信息
[root@linux ~]# grep "[0-9a-zA-Z]" ~/oldboy_test.txt
——4.1.9 尖号和中括号组合使用 : [^]^[]
1)对中括号里面匹配的字符信息进行排除
grep "[^0-9a-zA-Z]" ~/oldboy_test.txt --- 将字母数字都排除,只留下符号信息
[root@linux ~]# grep "[^0-9a-zA-Z]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
2)尖号和中括号组合使用 : ^[]
以中括号里面匹配的字符作为一行开头的字符
[root@linux ~]# grep "^[Im]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
—4.2 正则符号注意事项
1)按照每行信息进行过滤处理
2)注意正则表达符号禁止中文
3)附上颜色信息进行正则过滤 --color=auto/--color
4)基础正则符号可以被三剑客命令直接识别 grep sed awk
5)扩展正则符号不可以被三剑客命令中老二和老三直接识别
sed命令想识别正则符号: sed -r
grep命令想识别正则符号: egrep / grep -E
—4.3 扩展正则符号
——4.3.1 加号符号 +
1)匹配加号前面一个字符连续出现1次或者多次
[root@linux ~]# egrep "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "[0-9]+" ~/oldboy_test.txt -o
51
49000448
4900000448
终极目标
cat >>~/oldboy_test02.txt<<EOF
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
EOF
问题解决方式:
[root@linux ~]# egrep -v "[0-9X]+" ~/oldboy_test02.txt
陈 oldboy
刘 oldgirl
[root@linux ~]# egrep "[^0-9X]+" ~/oldboy_test02.txt
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
——4.3.2 竖线符号:|
1)或者关系符号
[root@linux ~]# egrep "oldboy|oldbey" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 在配置文件可能有#信息,空行信息, 都要进行过滤掉不要显示
egrep -v "^#|^$" 文件名称
扩展: 如何利用sed/awk完成+/|信息过滤
1) 如何过滤数值信息
[root@linux ~]# sed -rn '/[0-9]+/p' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
[root@linux ~]# awk '/[0-9]/' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
2) 如何过滤两个字符串信息(oldboy oldbey)
[root@linux ~]# sed -nr '/oldboy|oldbey/p' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# awk '/oldboy|oldbey/' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
——4.3.3 小括号符号 ()
1)将多个字符信息进行汇总为一个整体
[root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
2)进行后向引用前向的一个操作(sed)
[root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g"
<123456>
[root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g"
<12><34><56>
企业实践应用:
01. 修改配置文件内容
[root@linux ~]# grep "^S.*UX=" /etc/selinux/config
SELINUX=disabled
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcingdisabled
[root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcing
说明: 可以将替换命令放入到脚本中,从而实现快速部署操作
02. 批量修改文件名称(作业)
oldboy01.txt
oldboy02.txt
oldboy03.txt
oldboy04.txt
oldboy05.txt
oldboy06.txt
oldboy07.txt
oldboy08.txt
oldboy09.txt
oldboy10.txt
将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
匹配括号中每一个字符,并且匹配的关系是或者的关系 需求: 找出文件中oldboy 和 oldbey两个单词信息 [root@linux ~]# grep "oldb[oe]y" ~/oldboy_test.txt I am oldboy teacher! my blog is http://oldboy.blog.51cto.com my god ,i am not oldbey,but OLDBOY! 企业应用: 找寻文件中字母 数字信息 [root@linux ~]# grep "[0-9a-zA-Z]" ~/oldboy_test.txt
——4.1.9 尖号和中括号组合使用 : [^]^[]
1)对中括号里面匹配的字符信息进行排除
grep "[^0-9a-zA-Z]" ~/oldboy_test.txt --- 将字母数字都排除,只留下符号信息
[root@linux ~]# grep "[^0-9a-zA-Z]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
2)尖号和中括号组合使用 : ^[]
以中括号里面匹配的字符作为一行开头的字符
[root@linux ~]# grep "^[Im]" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
—4.2 正则符号注意事项
1)按照每行信息进行过滤处理
2)注意正则表达符号禁止中文
3)附上颜色信息进行正则过滤 --color=auto/--color
4)基础正则符号可以被三剑客命令直接识别 grep sed awk
5)扩展正则符号不可以被三剑客命令中老二和老三直接识别
sed命令想识别正则符号: sed -r
grep命令想识别正则符号: egrep / grep -E
—4.3 扩展正则符号
——4.3.1 加号符号 +
1)匹配加号前面一个字符连续出现1次或者多次
[root@linux ~]# egrep "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "0+" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# grep -E "[0-9]+" ~/oldboy_test.txt -o
51
49000448
4900000448
终极目标
cat >>~/oldboy_test02.txt<<EOF
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
EOF
问题解决方式:
[root@linux ~]# egrep -v "[0-9X]+" ~/oldboy_test02.txt
陈 oldboy
刘 oldgirl
[root@linux ~]# egrep "[^0-9X]+" ~/oldboy_test02.txt
赵 110101199901045121
钱 110101199901045121
孙 11010119990104512X
李 110101299901045121
陈 oldboy
周 110101199981045121
吴 110101199901045121
郑 11010149990104512X
刘 oldgirl
王 110101199908045121
冯 110111199901045121
——4.3.2 竖线符号:|
1)或者关系符号
[root@linux ~]# egrep "oldboy|oldbey" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 在配置文件可能有#信息,空行信息, 都要进行过滤掉不要显示
egrep -v "^#|^$" 文件名称
扩展: 如何利用sed/awk完成+/|信息过滤
1) 如何过滤数值信息
[root@linux ~]# sed -rn '/[0-9]+/p' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
[root@linux ~]# awk '/[0-9]/' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
2) 如何过滤两个字符串信息(oldboy oldbey)
[root@linux ~]# sed -nr '/oldboy|oldbey/p' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# awk '/oldboy|oldbey/' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
——4.3.3 小括号符号 ()
1)将多个字符信息进行汇总为一个整体
[root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
2)进行后向引用前向的一个操作(sed)
[root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g"
<123456>
[root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g"
<12><34><56>
企业实践应用:
01. 修改配置文件内容
[root@linux ~]# grep "^S.*UX=" /etc/selinux/config
SELINUX=disabled
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcingdisabled
[root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcing
说明: 可以将替换命令放入到脚本中,从而实现快速部署操作
02. 批量修改文件名称(作业)
oldboy01.txt
oldboy02.txt
oldboy03.txt
oldboy04.txt
oldboy05.txt
oldboy06.txt
oldboy07.txt
oldboy08.txt
oldboy09.txt
oldboy10.txt
将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
1)匹配加号前面一个字符连续出现1次或者多次 [root@linux ~]# egrep "0+" ~/oldboy_test.txt my qq num is 49000448. not 4900000448. [root@linux ~]# grep -E "0+" ~/oldboy_test.txt my qq num is 49000448. not 4900000448. [root@linux ~]# grep -E "[0-9]+" ~/oldboy_test.txt -o 51 49000448 4900000448 终极目标 cat >>~/oldboy_test02.txt<<EOF 赵 110101199901045121 钱 110101199901045121 孙 11010119990104512X 李 110101299901045121 陈 oldboy 周 110101199981045121 吴 110101199901045121 郑 11010149990104512X 刘 oldgirl 王 110101199908045121 冯 110111199901045121 EOF 问题解决方式: [root@linux ~]# egrep -v "[0-9X]+" ~/oldboy_test02.txt 陈 oldboy 刘 oldgirl [root@linux ~]# egrep "[^0-9X]+" ~/oldboy_test02.txt 赵 110101199901045121 钱 110101199901045121 孙 11010119990104512X 李 110101299901045121 陈 oldboy 周 110101199981045121 吴 110101199901045121 郑 11010149990104512X 刘 oldgirl 王 110101199908045121 冯 110111199901045121
——4.3.2 竖线符号:|
1)或者关系符号
[root@linux ~]# egrep "oldboy|oldbey" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
企业应用: 在配置文件可能有#信息,空行信息, 都要进行过滤掉不要显示
egrep -v "^#|^$" 文件名称
扩展: 如何利用sed/awk完成+/|信息过滤
1) 如何过滤数值信息
[root@linux ~]# sed -rn '/[0-9]+/p' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
[root@linux ~]# awk '/[0-9]/' ~/oldboy_test.txt
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
not 4900000448.
2) 如何过滤两个字符串信息(oldboy oldbey)
[root@linux ~]# sed -nr '/oldboy|oldbey/p' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# awk '/oldboy|oldbey/' ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
——4.3.3 小括号符号 ()
1)将多个字符信息进行汇总为一个整体
[root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
需求: 找出文件中oldboy 和 oldbey两个单词信息
[root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
2)进行后向引用前向的一个操作(sed)
[root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g"
<123456>
[root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g"
<12><34><56>
企业实践应用:
01. 修改配置文件内容
[root@linux ~]# grep "^S.*UX=" /etc/selinux/config
SELINUX=disabled
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config
[root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcingdisabled
[root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config
SELINUX=enforcing
说明: 可以将替换命令放入到脚本中,从而实现快速部署操作
02. 批量修改文件名称(作业)
oldboy01.txt
oldboy02.txt
oldboy03.txt
oldboy04.txt
oldboy05.txt
oldboy06.txt
oldboy07.txt
oldboy08.txt
oldboy09.txt
oldboy10.txt
将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
1)将多个字符信息进行汇总为一个整体 [root@linux ~]# egrep "(oldboy)" ~/oldboy_test.txt I am oldboy teacher! my blog is http://oldboy.blog.51cto.com 需求: 找出文件中oldboy 和 oldbey两个单词信息 [root@linux ~]# egrep "(oldboy)|(oldbey)" ~/oldboy_test.txt I am oldboy teacher! my blog is http://oldboy.blog.51cto.com my god ,i am not oldbey,but OLDBOY! [root@linux ~]# egrep "oldb(o|e)y" ~/oldboy_test.txt I am oldboy teacher! my blog is http://oldboy.blog.51cto.com my god ,i am not oldbey,but OLDBOY! 2)进行后向引用前向的一个操作(sed) [root@linux ~]# echo "123456"|sed -r "s#(.*)#<\1>#g" <123456> [root@linux ~]# echo "123456"|sed -r "s#(..)(..)(..)#<\1><\2><\3>#g" <12><34><56> 企业实践应用: 01. 修改配置文件内容 [root@linux ~]# grep "^S.*UX=" /etc/selinux/config SELINUX=disabled [root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#g" /etc/selinux/config [root@linux ~]# sed -rn "s#(^S.*UX=)#\1enforcing#gp" /etc/selinux/config SELINUX=enforcingdisabled [root@linux ~]# sed -rn "s#(^S.*UX=).*#\1enforcing#gp" /etc/selinux/config SELINUX=enforcing 说明: 可以将替换命令放入到脚本中,从而实现快速部署操作 02. 批量修改文件名称(作业) oldboy01.txt oldboy02.txt oldboy03.txt oldboy04.txt oldboy05.txt oldboy06.txt oldboy07.txt oldboy08.txt oldboy09.txt oldboy10.txt 将以上文件扩展名修改为.jpg
——4.3.4 大括号符号 {}
指定花扩号前一个字符连续匹配多少次
* 连续匹配 0 次 或 多次
+ 连续匹配 1 次 或 多次
1) {n,m} n表示最少连续匹配多少次 m表示最多连续匹配多少次
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,4}" ~/oldboy_test.txt -o
000
0000
2) {n} n表示只连续匹配n次
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3}" ~/oldboy_test.txt -o
000
000
3) {n,} n表示至少连续匹配n次,至多没有限制
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt
my qq num is 49000448.
not 4900000448.
[root@linux ~]# egrep "0{3,}" ~/oldboy_test.txt -o
000
00000
4) {,m} m表示至多连续匹配n次,至少0次
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@linux ~]# egrep "0{,3}" ~/oldboy_test.txt -o
000
000
00
[root@linux ~]# egrep "0{,4}" ~/oldboy_test.txt -o
000
0000
0
——4.3.5 问号符号 ?
* + {}
表示匹配问号前面一个字符出现0次或者1次
cat >>~/oldboy_test03.txt<<EOF
gd
god
good
goood
gooood
EOF
演示说明:
[root@linux ~]# grep "o*" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# grep "o+" ~/oldboy_test03.txt
[root@linux ~]# egrep "o+" ~/oldboy_test03.txt
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt
gd
god
good
goood
gooood
[root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o
o
o
o
o
o
o
o
o
o
o
* + {} 表示匹配问号前面一个字符出现0次或者1次 cat >>~/oldboy_test03.txt<<EOF gd god good goood gooood EOF 演示说明: [root@linux ~]# grep "o*" ~/oldboy_test03.txt gd god good goood gooood [root@linux ~]# grep "o+" ~/oldboy_test03.txt [root@linux ~]# egrep "o+" ~/oldboy_test03.txt god good goood gooood [root@linux ~]# egrep "o?" ~/oldboy_test03.txt gd god good goood gooood [root@linux ~]# egrep "o?" ~/oldboy_test03.txt -o o o o o o o o o o o