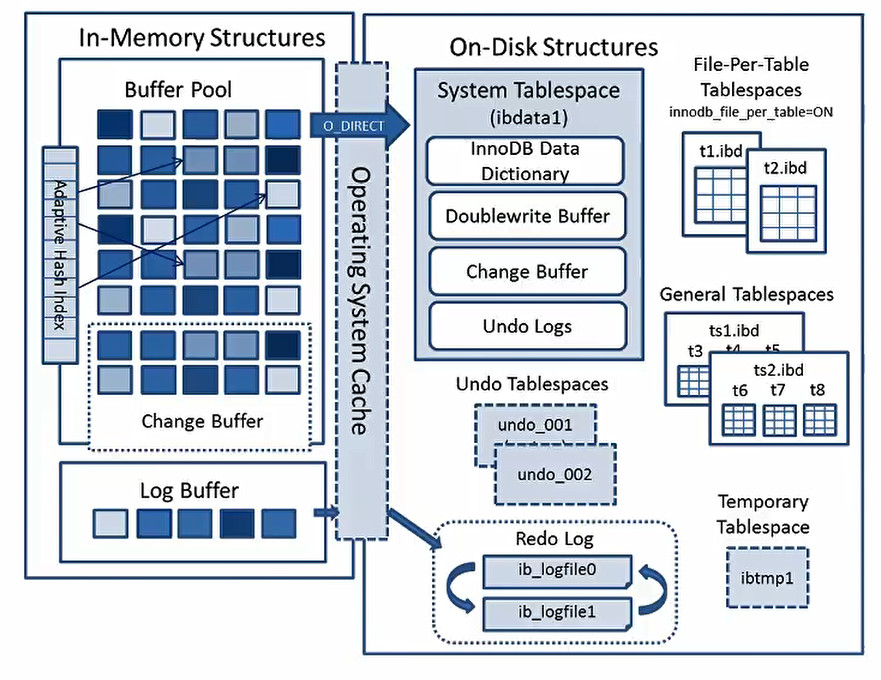
1.MySQL索引的自由化-AHI(自适应HASH索引)
MySQL的InnoDB引擎,能够创建只有BTREE AHI作用:自动评估“热”的内存多音page,生成HASH索引表。帮助InnoDB快速读取索引页,加快索引读取的速度,相当于索引的索引。
2.MySQL的索引自由化-change buffer
比如insert,update,delete一行数据,对于聚簇索引会立即更新,对于辅助索引,不是实时更新的. 在Innodb内存中,加入了insert buffer(会话),现在版本叫change buffer change buffer 功能是临时缓冲辅助索引需要的数据更新。 当我们需要查询新insert的数据,会在内存中进行merge(合并)操作,此时辅助索引是全新的。 怎么知道用户在访问的时候,走了我们设置的索引,遇到双11那种大量访问时,索引设置不及时, 应该如何解决,如何知道用户经常访问的数据信息是哪些? 双11的时候,并发度太高,提前1~2周将热点商品数据灌入到Tair(radis,memcached)集群中, KAFKA处理队列问题。核心就是对列和缓存的使用。
3.ICP索引下推
作用:解决了,联合索引只能部分应用情况。 为了使减少没必要的数据页被扫描。 将不走索引的条件,在 engine层取数据之前先做c二次过滤。 一些无关数据就会被提前过滤掉。 index(a,b,c) select * from t1 where a= and c= 在server先做a列过滤条件的索引优化,在将c列的过滤下推导engine层先做过滤,加载数据页。
4.MRR muti range read
set global optimizer_switch='mrr=on,mrr_cost_based=off'; 辅助索引---回表--->聚簇索引 转换为 辅助索引-->sort id-->回表->聚簇索引
5.SNLJ
通过left join强制驱动表
6.BNLJ
在A和B关联条件匹配时,不再一次一次进行循环。 而是采用一次性将驱动表的关联值和费驱动表匹配,一次性返回结果。 主要优化了,CPU消耗,减少了IO次数。
7.BKA
主要是来优化非驱动表的关联列有辅助索引。