文章目录
聚簇索引(C)B树索引
前提
簇就是段区页中的区,64个page=1M (1)表中设置了主键,主键列就会自动被作为聚集索引.比如ID not null primary key (2)如果没有主键,会选择唯一键unique作为聚集索引. (3)以上都没有,生成隐藏聚簇索引
过程
(1) 在建表时,设置了主键列(ID) (2) 在将来录入数据时,就会按照ID列的顺序存储到磁盘上.(我们又称之为聚集索引组织表) (3) 将排好序的整行数据,生成叶子节点.可以理解为,磁盘的数据页就是叶子节点
作用
有了聚簇索引之后,将来插入的数据行,在同一个区内,都会按照ID值的顺序,有序在磁盘存储数据。 innodb表指聚簇索引组织存储数据表
构建过程画图说明
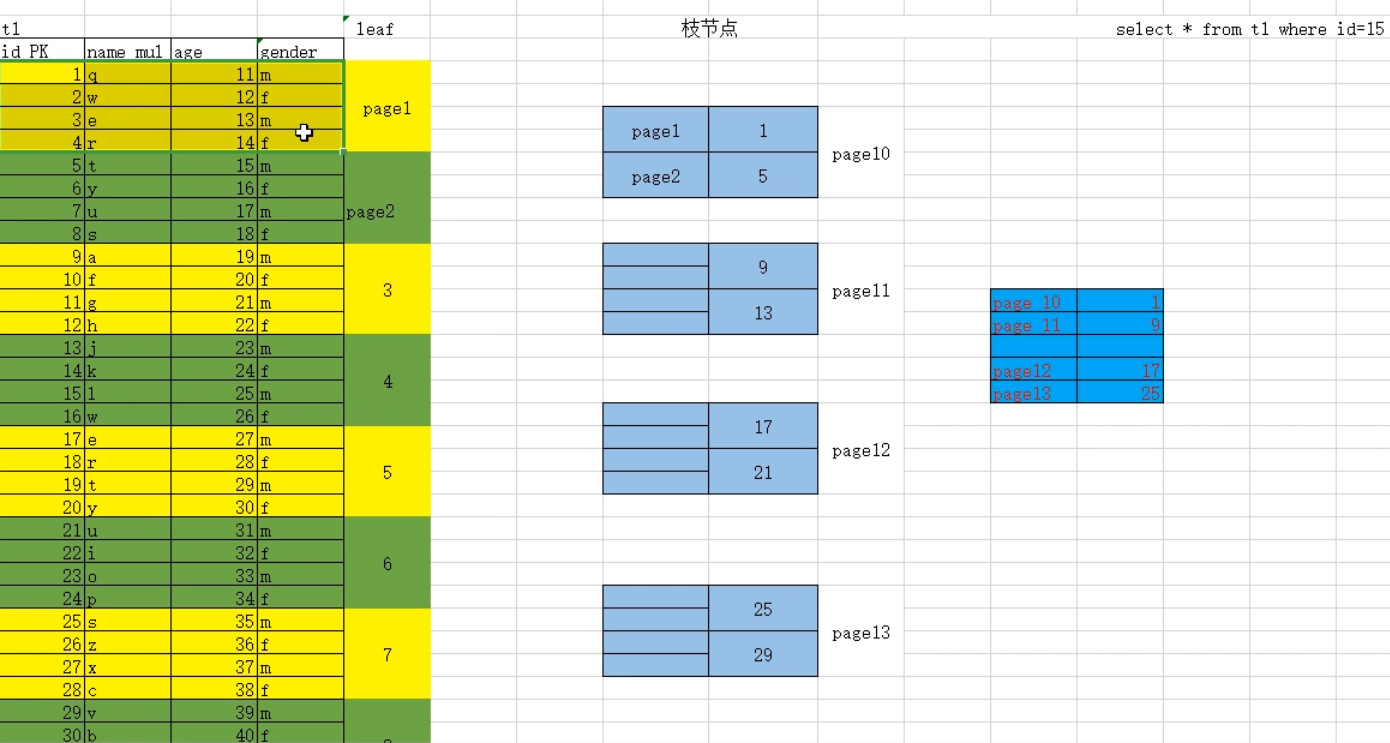
辅助索引BTREE结构
说明
使用普通列作为条件构建的索引,需要后期人为创建。 将辅助索引列值+ID主键值,构建辅助索引B树结构。
作用
优化非聚簇索引列之外的查询条件,比如name列
构建过程画图说明
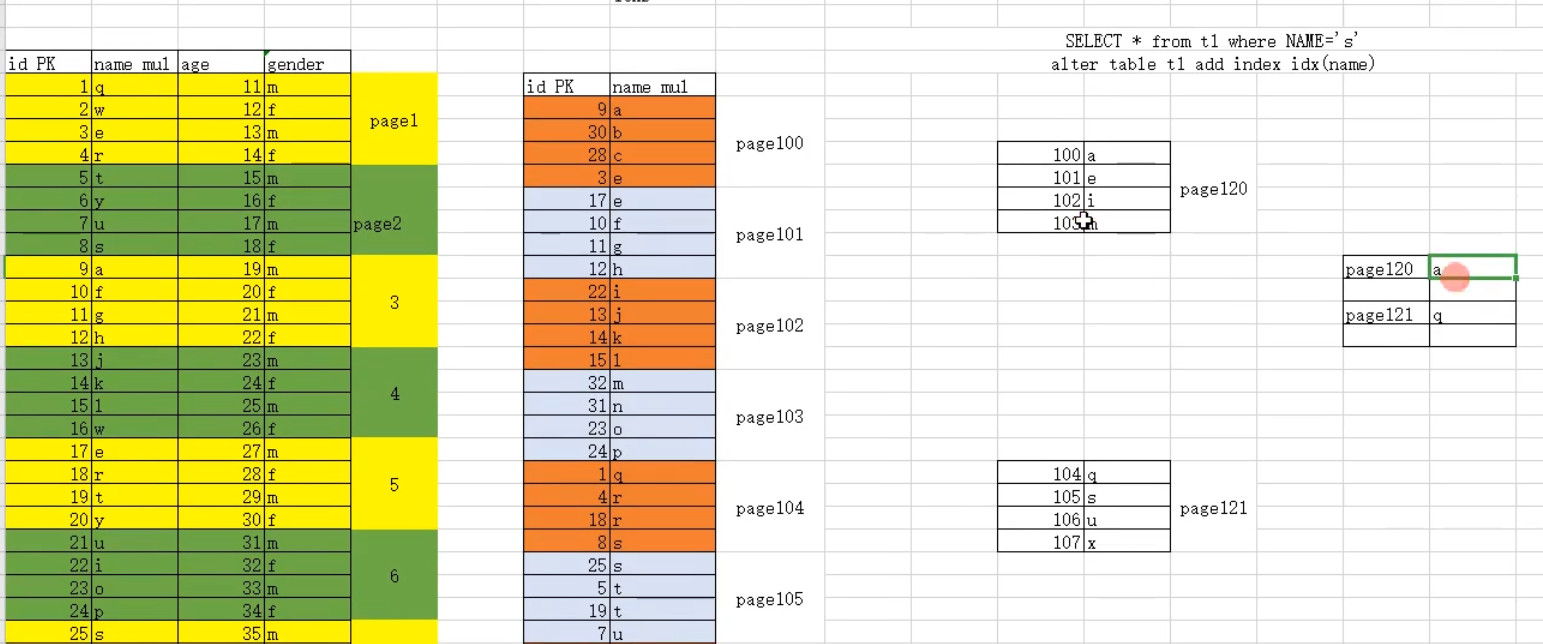
辅助索引细分
1.普通的单列辅助索引 2.联合索引:多个列作为索引条件,生成索引树,理论上设计的好的,可以减少大量的回表查询 说明:使用多列组合一个索引,最左原则。idx(a,b,c) a.查询条件中,必须要包含最左列a列 b.建立索引时,一定要选择重复值少的列,作为最左列 例如:idx(a,b,c)相当于a,ab,abc三个索引都被创建3.前缀索引 前缀索引时针对于,我们所选择索引列值长度过长,会导致索引树的高度增高。会导致索引应用时,需要读取更多的索引数据页。 所以可以选择大字段的前面部分字符作为索引列生成条件。 mysql中建议索引树高度3-4层
B+TREE索引树高度影响因素
1.索引字段较长->前缀索引
2.数据行过多->分区表(分区表在更新数据的时候容易锁表),现在更多使用归档表,归档多张表,按照日期做历史数据(手工或者pt-arvhive),
或者分布式结构
3.数据类型->选择合适的数据类型(比如varchar() char() enmu() 变长长度字符串)
解决方案:变长字符串使用varchar,enum类型的使用enum ('山东','河北','黑龙江','吉林','辽宁','陕西'......)
高度影响性能,千万行以下的一般3-4层为最佳
回表查询
MySQL用来存储数据行的逻辑结构,表的数据行最终存储到了很多的PAGE上。
Innodb存储引擎,会按照聚簇索引有序的组织存储表数据到各个区的连续的页上。
这些连续数据页,成为了聚簇索引的叶子节点,你可以认为聚簇索引就是原表数据。
所以,回表即是回聚簇索引。
用户使用辅助索引列作为条件查询时,首先扫描辅助索引的B树,如果辅助索引能够完全覆盖我们的查询结果时,就不需要回表。
如果不能完全覆盖到,只能通过得出的ID主键列,回到聚簇索引(回表)扫描,最终得到想要的结果。
影响:
1.IO量级表大
2.IOPS增大导致磁盘达到瓶颈
3。随机IO变多
减少回表:
1.将查询尽可能用ID主键列查询
2.设计合理的辅助索引(联合索引)
3.更精确地查询条件+联合索引
4.优化器算法:MGRR
MGRR相关参数
我们可以通过参数 optimizer_switch 的标记来控制是否使用MRR,当设置mrr=on时,表示启用MRR优化。mrr_cost_based 表示是否通过 cost base的方式来启用MRR.如果选择mrr=on,mrr_cost_based=off,则表示总是开启MRR优化。 参数read_rnd_buffer_size 用来控制键值缓冲区的大小。
索引失效
案例:同一条语句在查询很快的情况下,突然有一天查询特别慢的原因 由于表的数据更新,修改,删除,插入等频繁,索引对于统计信息收集不准确,导致索引和磁盘数据行之间产生不对等的关系, 解决办法就是索引drop掉,重建索引;经常会发生更新的列尽量不做索引,因为经常更新则需要经常维护,对性能的影响会比较大。
更新数据时,会对索引又影响吗?
比如insert,update,delete一行数据,对于聚簇索引会立即更新,对于辅助索引,不是实时更新的. 在Innodb内存中,加入了insert buffer(会话),现在版本叫change buffer change buffer 功能是临时缓冲辅助索引需要的数据更新。 当我们需要查询新insert的数据,会在内存中进行merge(合并)操作,此时辅助索引是全新的。 怎么知道用户在访问的时候,走了我们设置的索引,遇到双11那种大量访问时,索引设置不及时,应该如何解决,如何知道用户经常访问的数据信息是哪些? 双11的时候,并发度太高,提前1~2周将热点商品数据灌入到Tair(radis,memcached)集群中,KAFKA处理队列问题。核心就是对列和缓存的使用。
--------------------------------------------------------------------
MySQL 将根据辅助索引获取的结果集根据主键进行排序,将乱序化为有序,可以用主键顺序访问基表,将随机读转化为顺序读,
多页数据记录可一次性 读入或根据此次的主键范围分次读入,以减少IO操作
,提高查询效率。 辅助索引又称为二级索引 (1). 索引是基于表中列的值(索引键值)生成的B树结构 (2). 首先提取此列所有的值,进行自动排序 (3). 将排好序的值,均匀的分布到索引树的叶子节点中(16K) (4). 然后生成此索引键值所对应得磁盘数据页的指针 (5). 生成枝节点和根节点,根据数据量级和索引键长度,生成合适的索引树高度 已知表有id、name、age、gender四列,select * from t1 where id=10; 问题: 基于索引键做where查询,对于id列是顺序IO,但是对于其他列的查询,可能是随机IO? 因为没有主键或者唯一键,B树根据索引键值无法找到唯一数据行
辅助索引-->ID-->聚集索引,带来大量的随机IO。 减少回表次数,可以用联合索引和MRR来解决问题。 联合索引减少回表次数的表现就是精准的锁定ID。 MRR:辅助索引-->回表-->聚集索引,在回表之前自动将主键值集中后排序,一次性回表查询,减少回表次数, 随机IO可能转换为顺序IO MRR的全称是Multi-Range Read Optimization,是优化器将随机IO转化为顺序IO以降低查询过程中IO开销的一种手段, 这对IO-bound类型的SQL语句性能带来极大的提升,适用于range eq_ref类型的查询 MGRR优化的几个好处 使数据访问有随机变为顺序,查询辅助索引, 首先把查询结果按照主键进行排序,按照主键的顺序进行书签查找, 减少缓冲池中页被替换的次数,批量处理键值的操作
聚集索引和辅助索引构成结论
1.聚集索引只能有一个,非空唯一,一般时主键 2.辅助索引,可以有多个,是配合聚集索引使用的,看查询条件用的多的列,建立辅助索引 3.聚集索引叶子节点,就是磁盘的数据行存储的数据页 4.MySQL是根据聚集索引组织存储数据,数据存储时就是按照聚集索引的顺序进行存储数据 5.辅助索引,只会提取索引键值,进行自动排序生成B树结构 6.有聚集索引的时候,辅助索引顺序为叶子节点-->聚集索引叶子节点,没有聚集索引的时候,辅助索引顺序为叶子节点-->磁盘数据页查询 7.聚集索引和辅助索引对有大量的排序的需求的列可以优化排序操作(order by group by join)